文献阅读笔记-Study of Deep Learning Techniques for Side-Channel Analysis and Introduction to ASCAD Database
文章信息
-
作者:Ryad Benadjila, Emmanuel Prouff, Rémi Strullu, Eleonora Cagli and Cécile Dumas
-
单位:CEA, LETI, MINATEC Campus, F-38054 Grenoble, France
-
出处:ePrint
-
标题:Study of Deep Learning Techniques for Side-Channel Analysis and Introduction to ASCAD Database
文章内容
这篇论文属于是入门必读了,了解深度学习结合侧信道要做什么,先从该论文入手最好。
背景
在当时将侧信道攻击与传统机器学习相结合,已经被证实相较于模板攻击有许多优势,但超参数的设计往往被保密,造成了论文中的方法以及结果不可复现。
目的及方法
为了解决上述问题,作者将自己分析到的AES能量迹数据集公开(ASCAD),并且解决了在该数据集上CNN、MLP模型的超参数选择问题以及模型评估指标。
评估指标
| 指标 | 含义 |
|---|---|
| 秩函数 | |
| 准确性 | |
| 计算时间 | - |
秩函数
十折交叉验证
https://i4mhmh.cn/archives/undefined.html
ASCAD
具体数据集采集工作暂不去研究,以后应该也不会补。
作者将此数据集打包为h5格式,调用数据的时候最好将其中的数据打包为np或tf的格式。数据集解压后分为三个主目录,每个不同设备上采集的数据集的结构均为Profiling_traces与Attack_traces两个索引,每个索引下存放三个小数据集traces、label、metadata
MLP
Url:
| 模型 | 数值 |
|---|---|
| 层数 | 6 |
| 神经元 | 200 |
| 激活函数 | ReLU |
| 优化器 | RMSProp |
| 超参数 | - |
| 学习率 | 0.00001 |
| epochs -> batch | - |
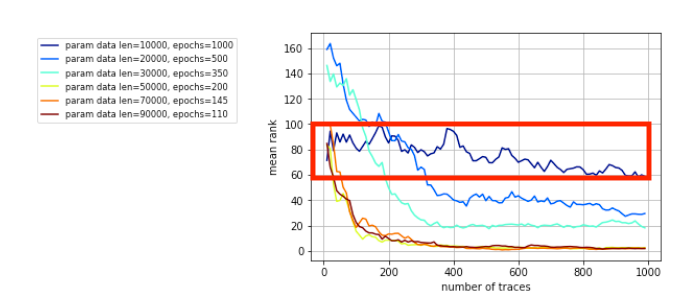
如图一所示,在其他条件不变的情况下,对epoch的次数对结mean rank(MR)的影响进行研究,发现在epoch等于一千的时候,无论是多少次迭代,都无明显的收敛效果(红框所示),这里作者表述实验时800以上就是此效果,~说明小批量学习在此模型中的表现欠佳~ 什么也说明不了,只能说给epochs设定了一个上限 。这里params data len(pdl)是能量迹的条数参数化表示,不同epoch的pdl不同,目的是为了保证最后运行的时间相同。
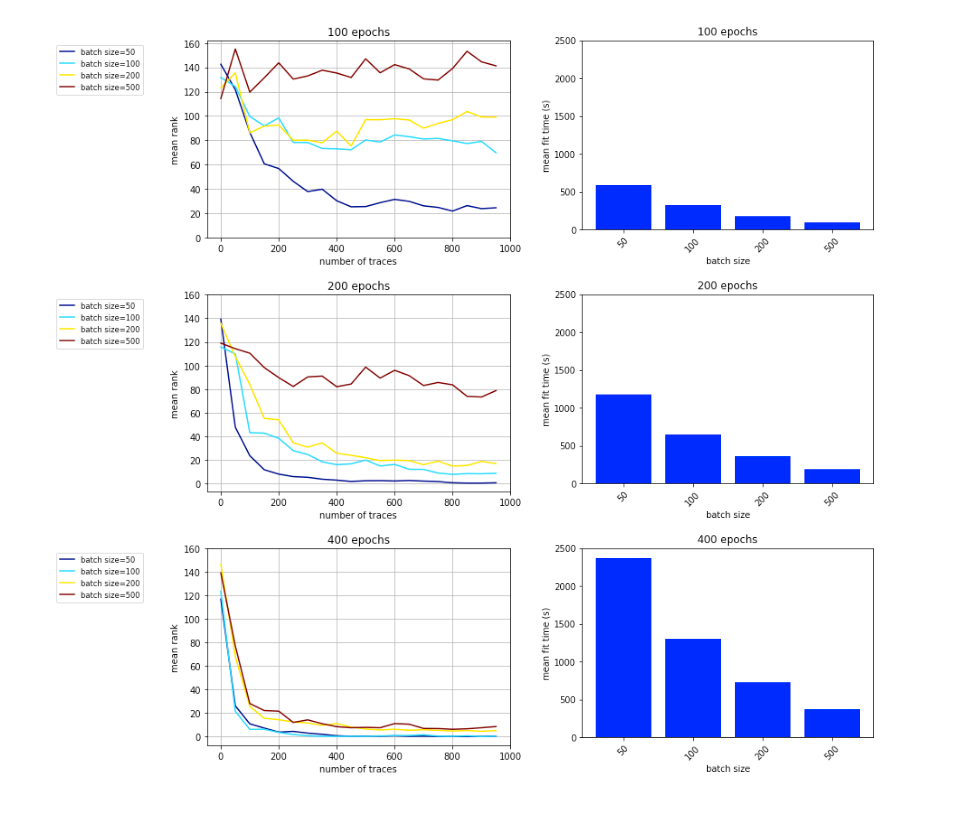
之后作者去搜索epoch与batchSize的最佳平衡参数,给出的结果表明在epochs=400,batch size=100时平均秩函数的收敛效果最好。
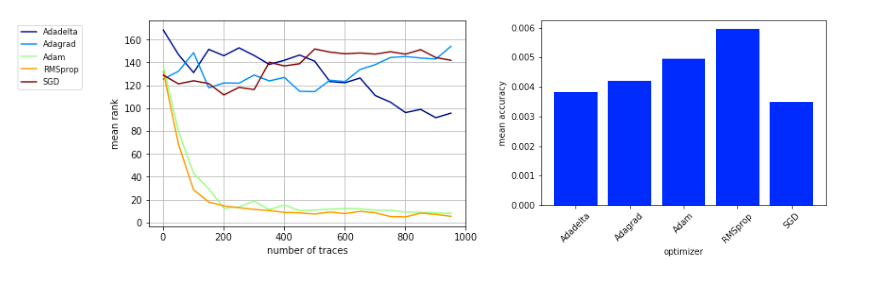
在相同条件下,作者测试了Adadeita、Adagrad、Adam、RMSprop、SGD等优化器对MR的影响,发现RMSprop优化器的效果最佳,结果如图3所示。
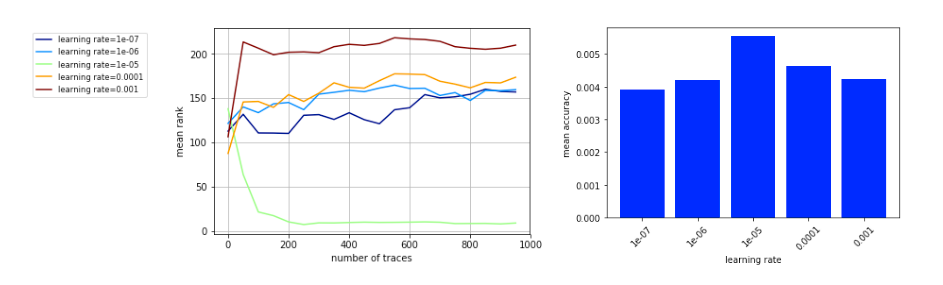
之后作者调整不同的学习率来寻求最优收敛,发现1e-05的效果最佳,结果如图4所示。
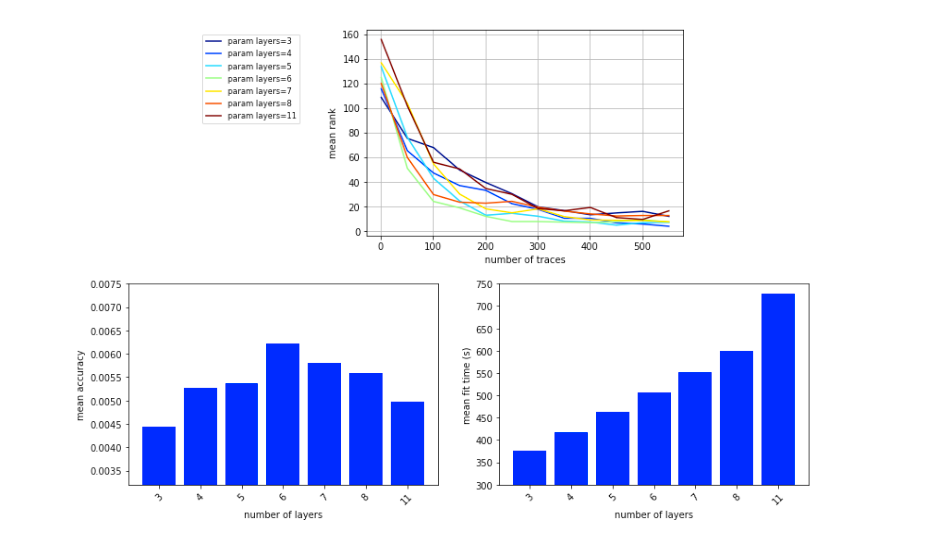
关于MLP的层数,作者选择3、4、5、6、7、8、11来对比,结果显示MLP层数为6的时候精度较高,如图5所示。
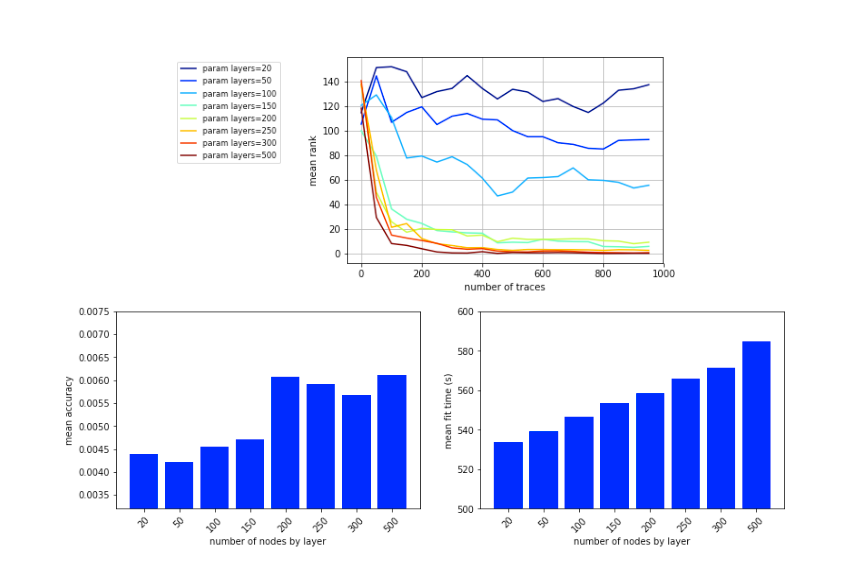
作者关于每层的神经元个数做了对比实验,发现当神经元个数大于200时,准确性会有波动且训练时间会增加,如图6所示。
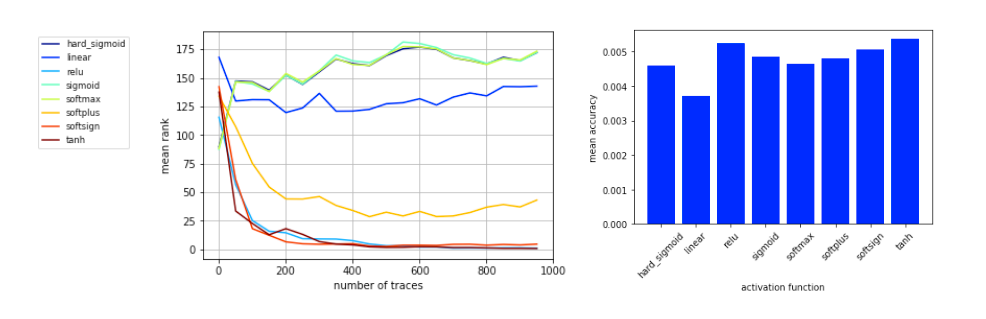
最后作者讨论了激活函数对于模型性能的影响,作者挑选了ReLU、tanh、softplus、softmax、softsign、sigmoid、lnear、hard_sigmoid等激活函数,最后这里作者说明ReLU函数的结果较好且相较于其他激活函数的训练时间最短。结果如图7所示。