
文献阅读笔记-One Network to rule them all. An autoencoder approach to encode datasets
文章信息
-
作者:Cristian-Alexandru Botocan
-
单位:EEMCS, Delft University of Technology, The Netherlands
-
出处:ePrint
-
标题:One Network to rule them all. An autoencoder approach to encode datasets
文章内容
背景
越来越多的研究证实了模板攻击在侧信道攻击中的有效性,而深度学习结合侧信道攻击,即在结合ML模型后性能较好。自CNN应用到侧信道攻击中后,相继有许多其他模型被提出,但统一的问题在于每个模型都可以在单一的数据集中表现良好,而当加密算法种类增加对于每个算法都要找到对应最佳模型,即对于不同数据集要找到不同的算法最优解的时间开销较大。
目的
作者引入Deep Fake的概念,通过AEs(AutoEncoders-自编码器)将数据集的特征进行压缩以减轻存储开销,主要目的是找到一个通用模型,对维度统一后的数据集进行攻击,这里统一的数据集与源数据在数量上相同,但维度参数完全不同。
结论
进行AE预处理后的数据集与未处理的数据集结果仍受模型的影响,对于不同的模型效果截然不同,在No Conv模型上获得了较大的性能提升。
实验与结果
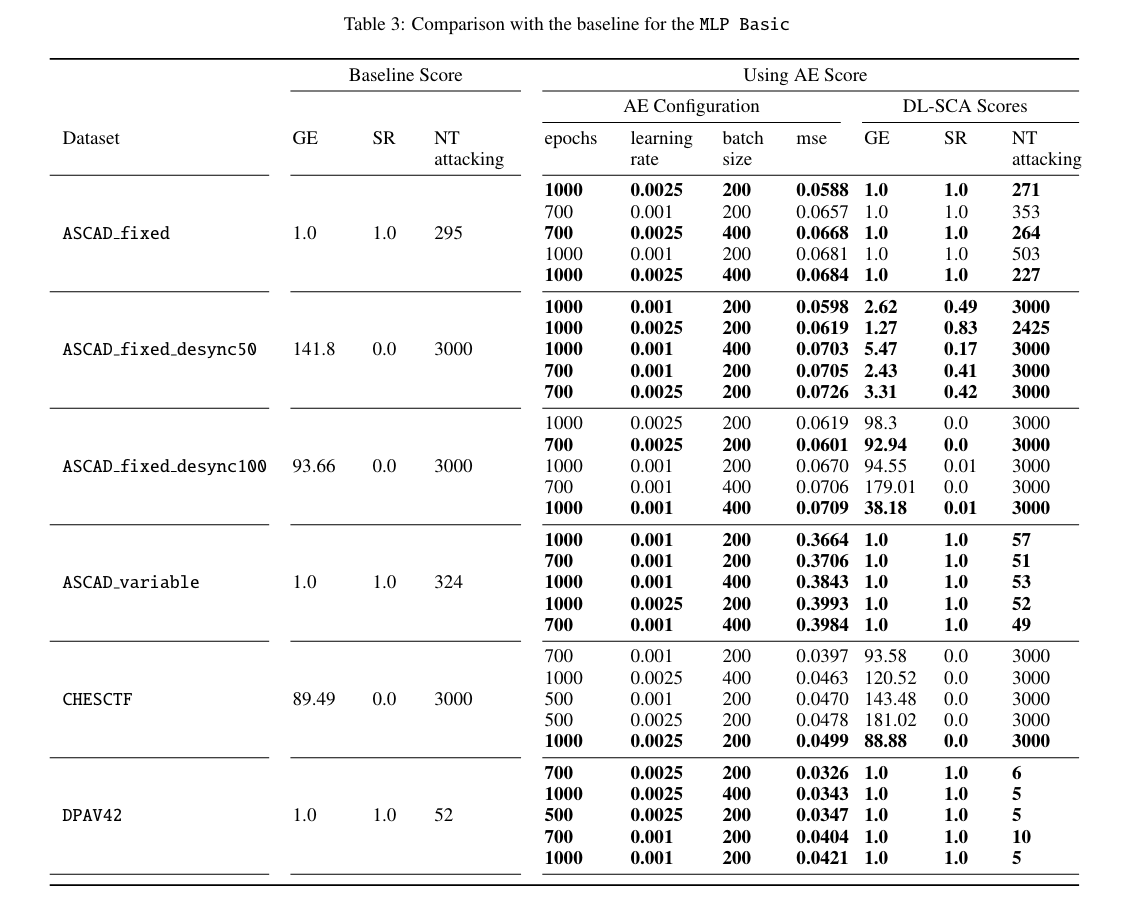
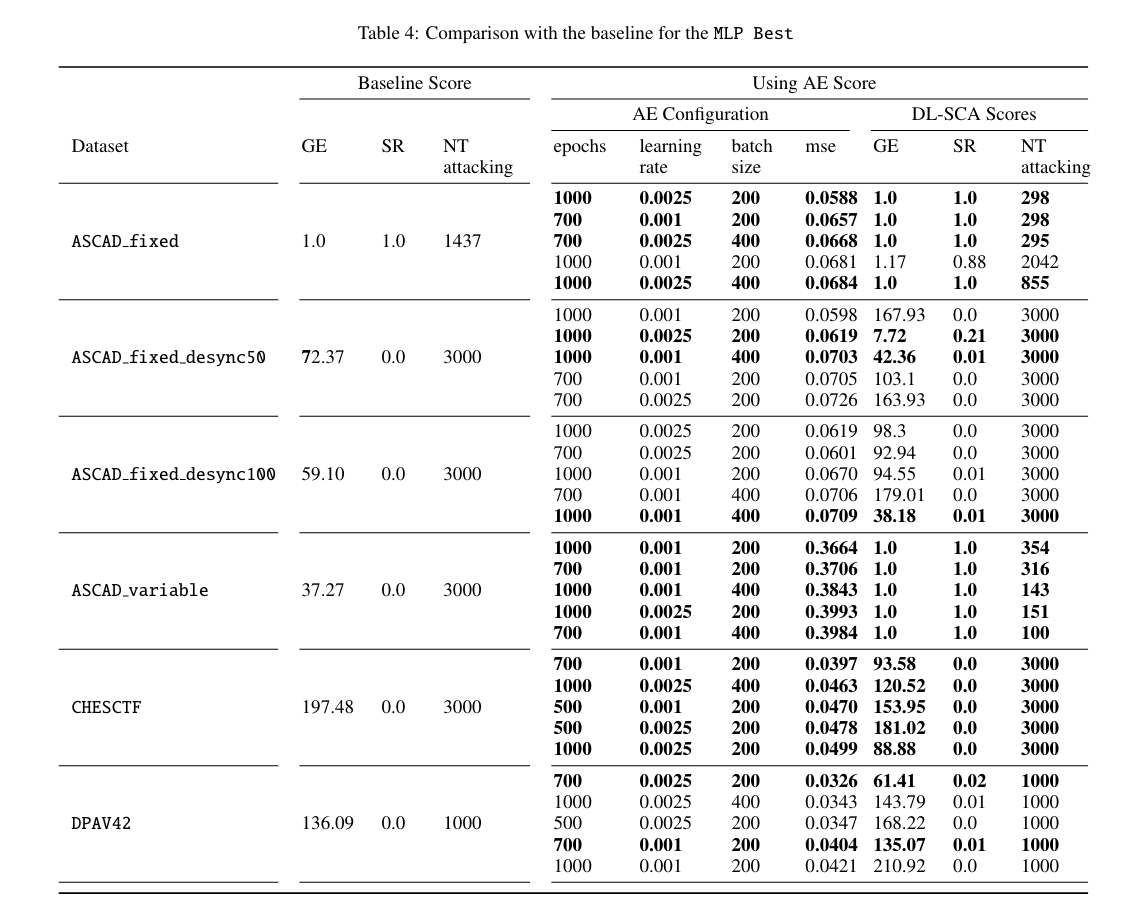
作者采Vanilla AE自编码器(结构如图1所示),优化器Adamax,Epochs={500, 700, 1000},学习率:0.01,0.001,0.0025,Batch_size={200, 400},Shuffle=True。模型为ML Basic、MLP Best、CNN Best、No Conv。评价指标为GE(Guess Entropy)、SR(Success Rate),GE收敛到1即为攻击成功。
| 数据集名称 | 介绍 | 地址 |
|---|---|---|
| ASCAD fixed key | 6w条能量迹,700个特征,算法:AES128,采集设备:ATMega8515 | https://github.com/ANSSI-FR/ASCAD |
| ASCAD fixed key with desynchronization | 人为的随机去同步 | - |
| ASCAD variable key | - | |
| CHESCTF | 1w条能量迹,65w个特征,算法:AES128,采集设备STM32, 作者提取了4k个特征。 | https://zenodo.org/record/3733418#.Yc2iq1ko9Pa |
| DPAV42 | 8w条能量迹,800个特征,算法:带掩码的AES128,采集设备:8-bit controller | https://www.dpacontest.org/v4/42_traces.php |
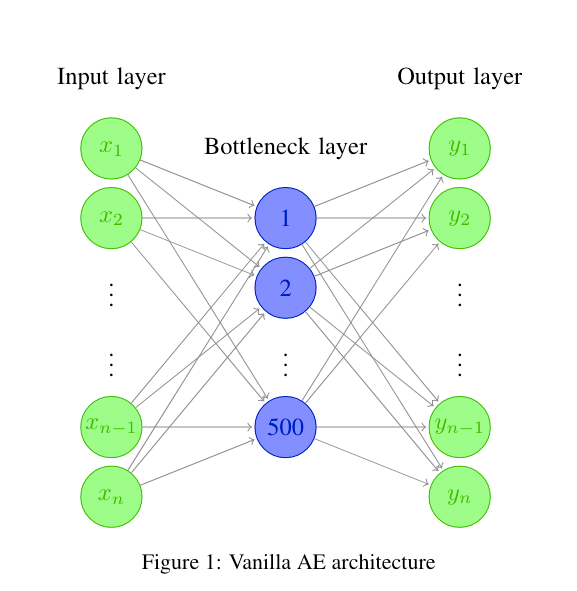
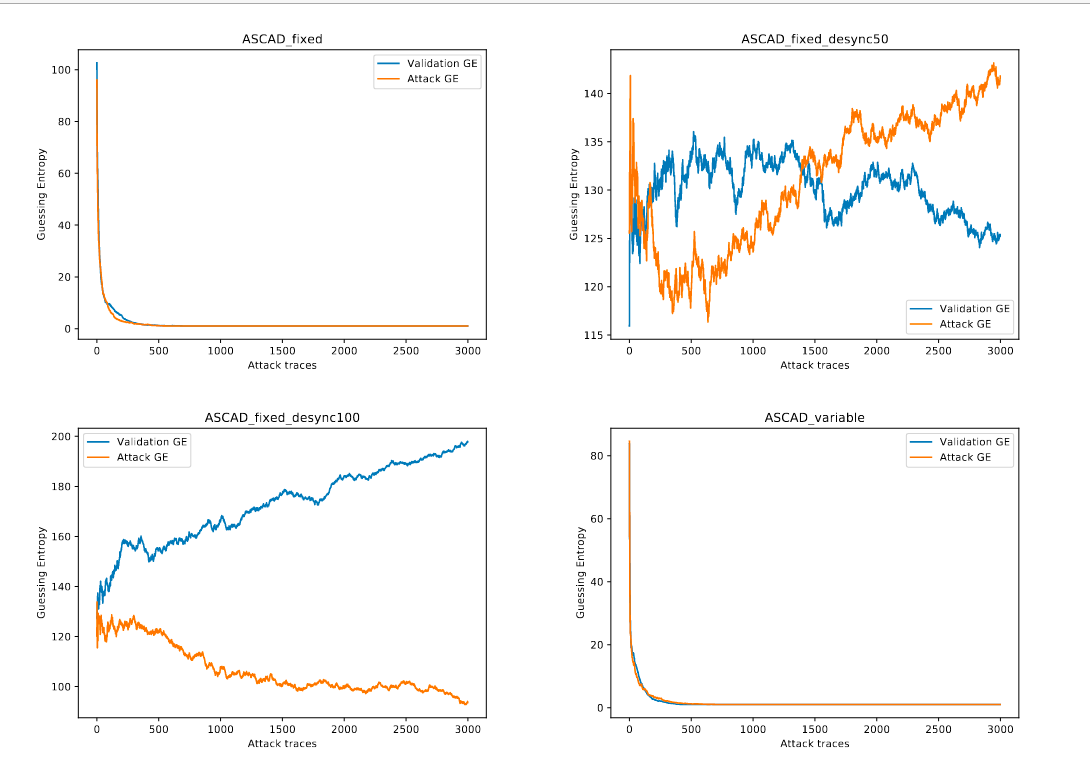
图2 为预处理与未预处理的数据集在MLP Basic模型上的表现,对于不采用对抗措施的ASCAD、DPAV42数据集无明显改进,且在使用了时钟抖动的数据集上GE无法收敛到1,在CHSCTF数据集上,作者将GE无法收敛归因于能量迹条数过少以至于学习不完4000个特征,造成数据集的破坏。因为相较于CHESCTF,DPAV42数据集上的800个特征以及8w条能量迹使得攻击效果较好。
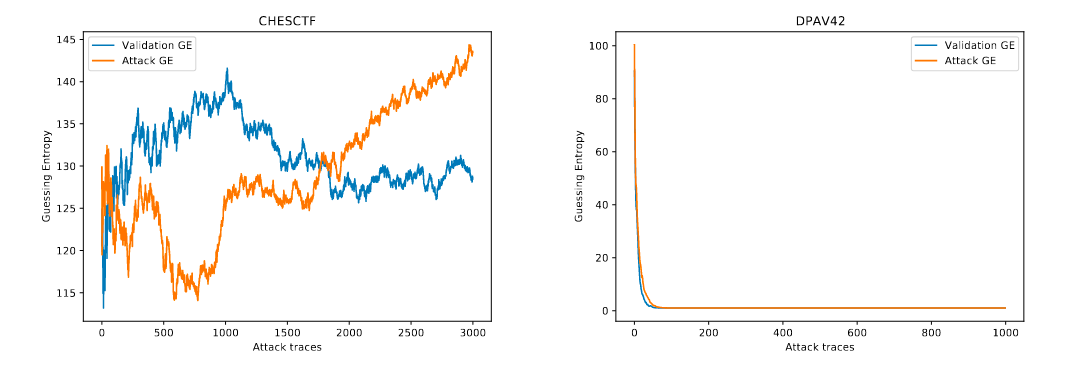
MLP Best是针对于ASCAD优化的模型,因此在图三中可以看出预处理后的GE收敛效果不明显甚至较差,而在CHESCTF上的收敛结果较好。
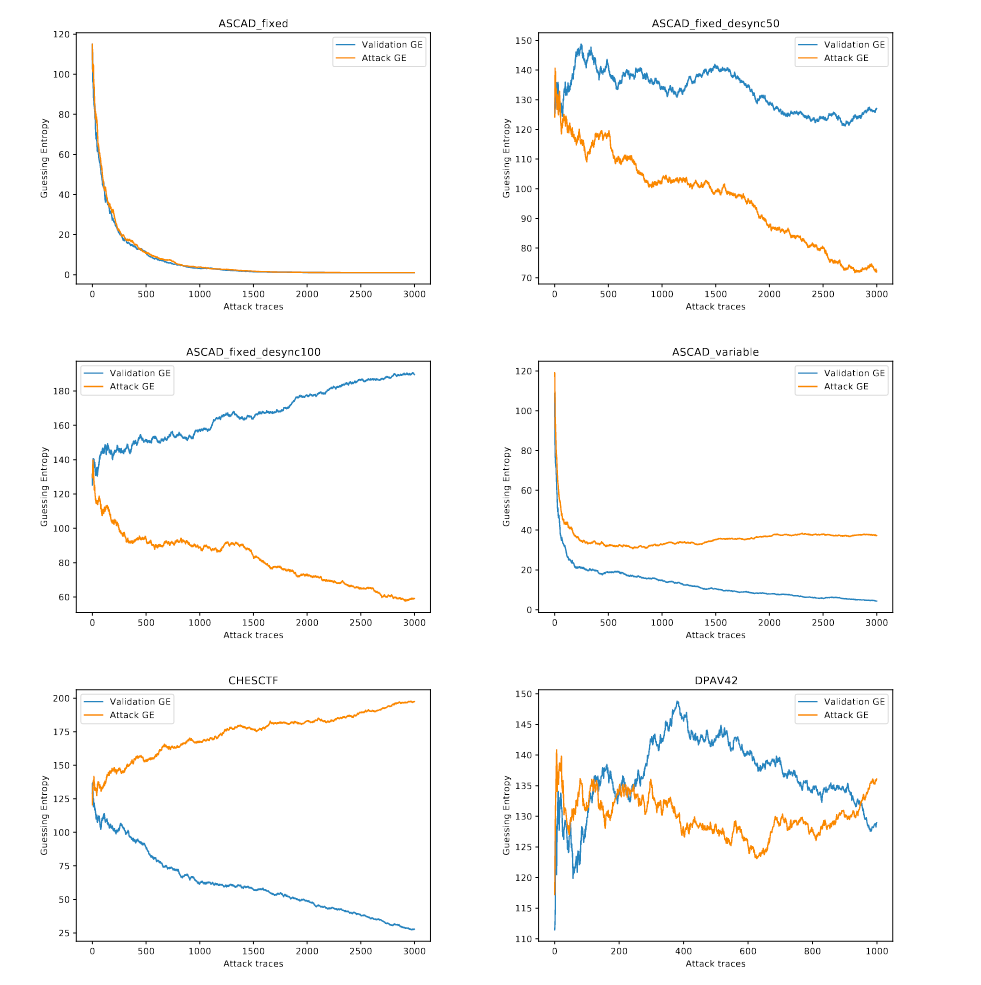
CNN Bset同样为带有防御措施的ASCAD数据集准备,在ASCAD_fixed_desync50/100上预处理的攻击效果反而较差。
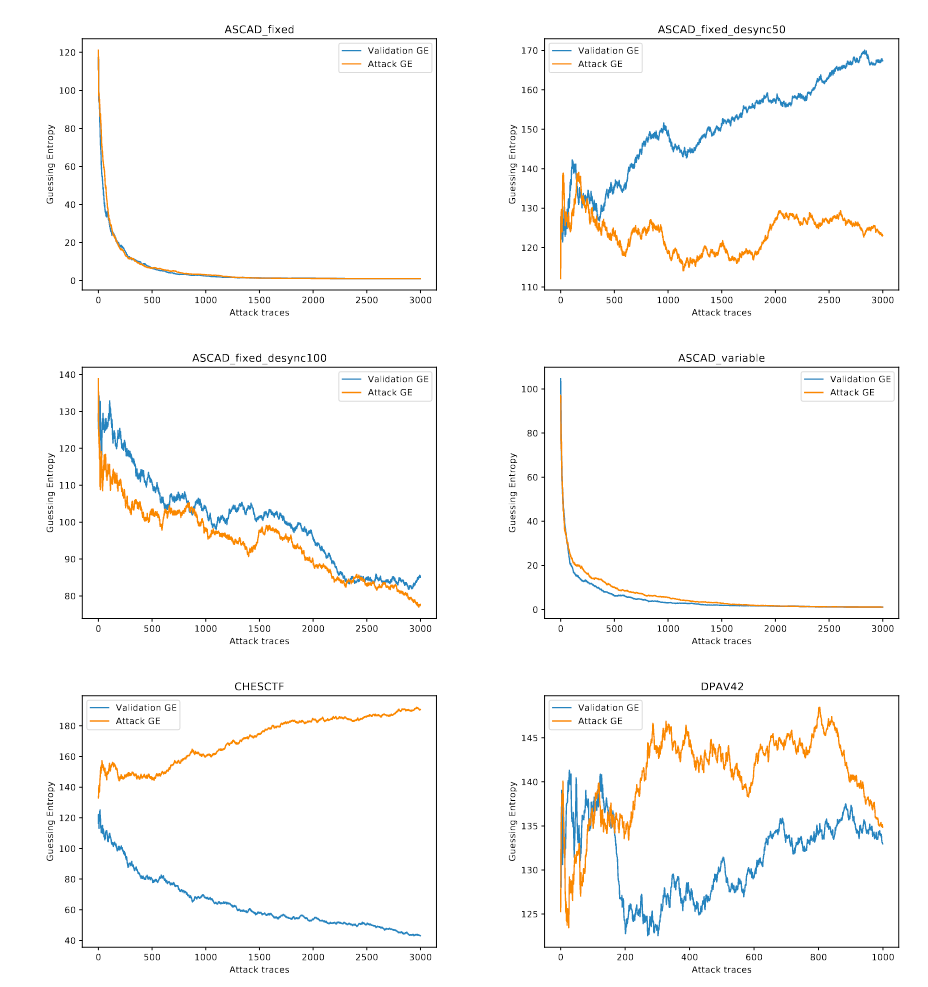
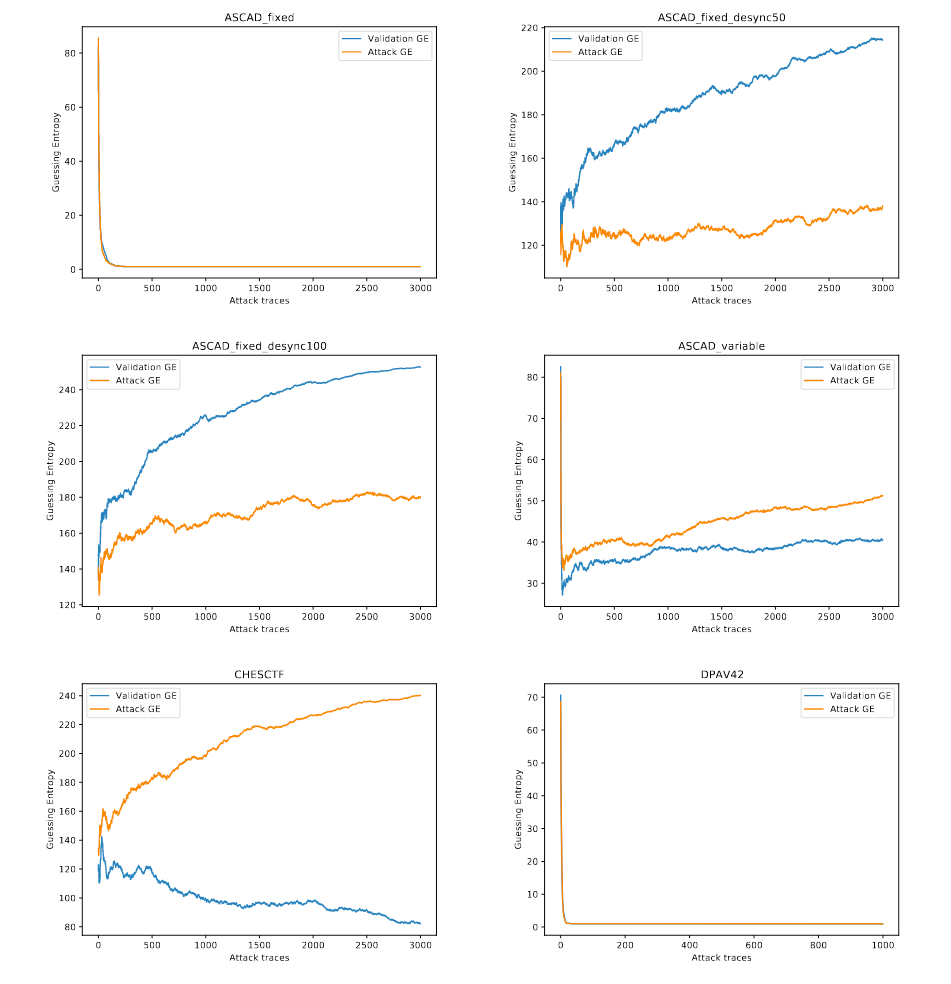
如图五所示,在ASCAD_variable与CHESCTF数据集中表现较好,GE收敛速度要优于未处理攻击。
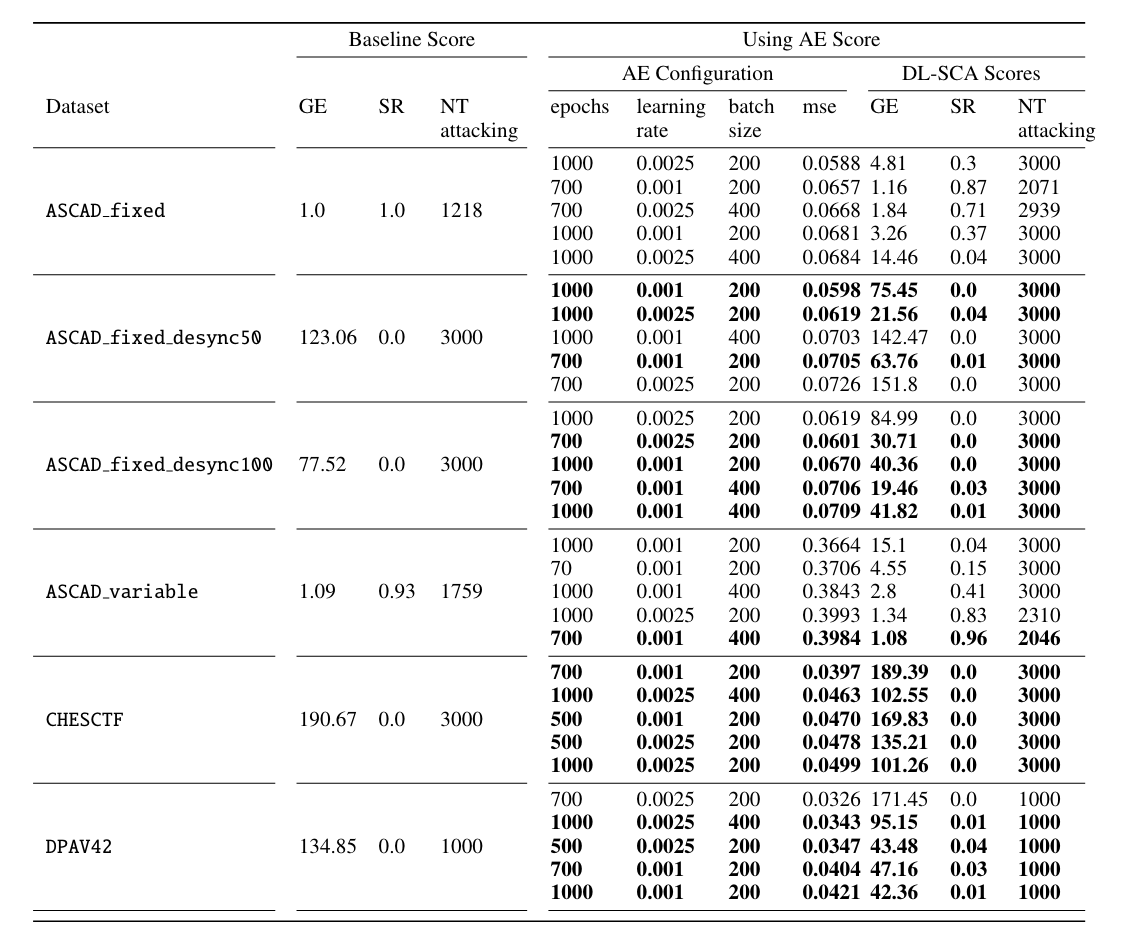
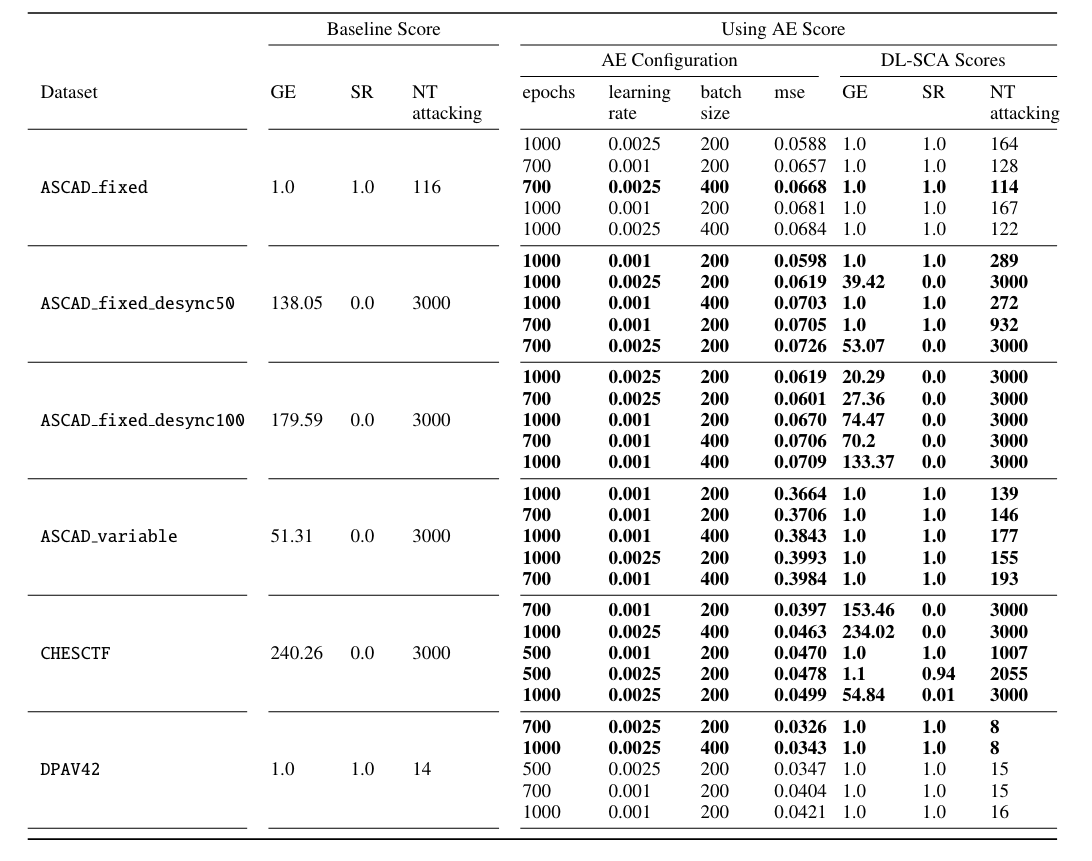
附数值表
NT attacking: NT - number of traces used for the attacking becomes smaller than the maximum set value.
总结
作者通过自编码器对数据集进行预处理,在不同模型、不同数据集的条件下进行评估,虽然结果并没有整体偏好,但在某方面有较大的提升,特别是在No Conv模型下。总体指出一个研究方向:统一模型,即要在同一个模型下能对多个数据集进行处理,要求找到最优压缩方法,对不同的数据集进行处理,得到整体较好的结果。
