
文献阅读笔记-On the Performance of Convolutional Neural Networks for Side-channel Analysis
文章信息
-
作者:Stjepan Picek, Ioannis Petros Samiotis, Annelie Heuser, Jaehun Kim, Shivam Bhasin, and Axel Legay
-
单位:代尔夫特理工大学
-
出处:[International Conference on Security, Privacy, and Applied Cryptography Engineering](https://link.springer.com/conference/space space) SPACE 2018
-
标题:On the Performance of Convolutional Neural Networks for Side-channel Analysis
写在前面
文章主要是做了实验来验证不同数据集上Naive Bayes、XGBoost、RF、MLP、CNN等代表性模型性能,给了实验数据,没源码。
文章内容
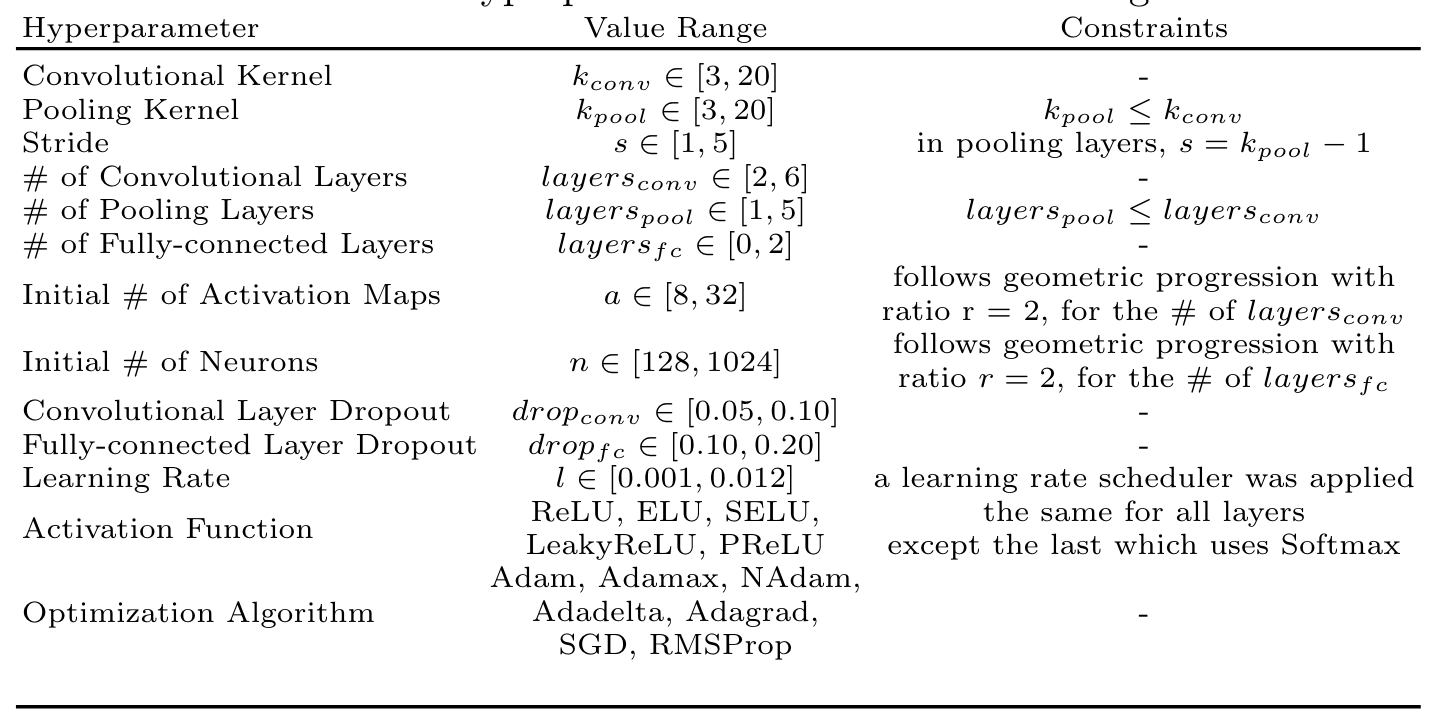
模型
模型的网格搜索字典
1 | MLP:{"activation":"ReLU, Tanh", |
CNN
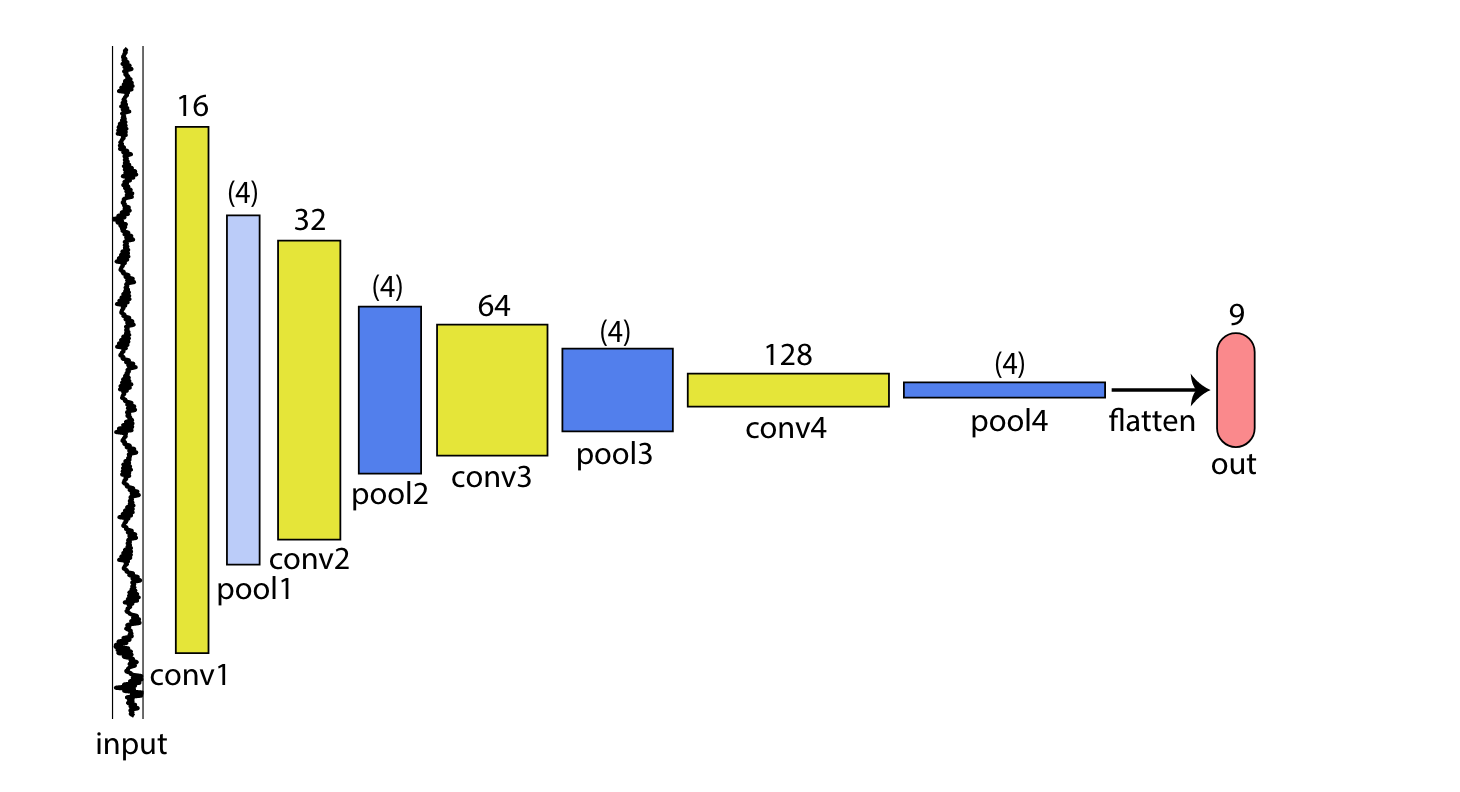
结果
利用HW4挑选50个特征,在DPAv4数据集不同的模型攻击准确率。
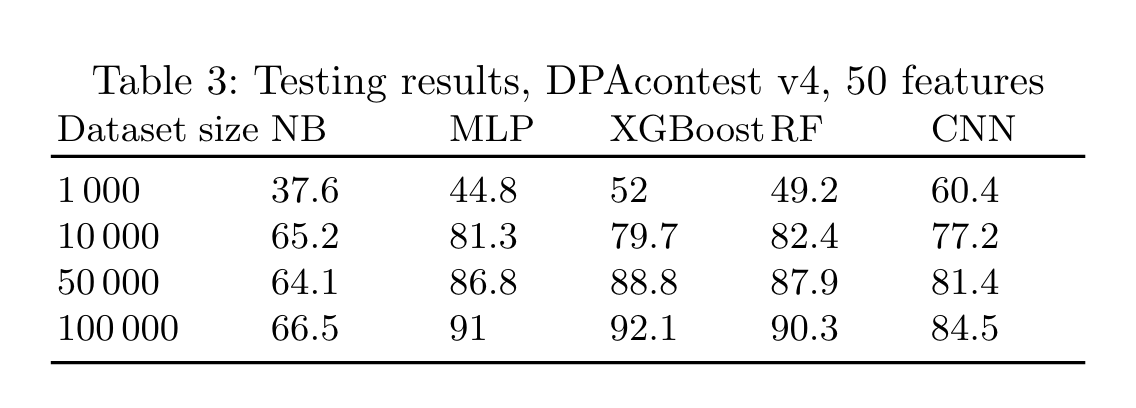
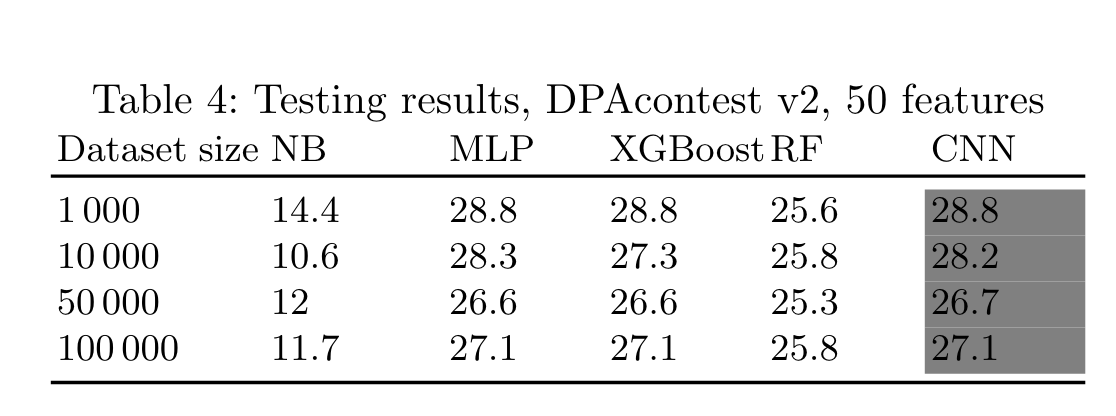
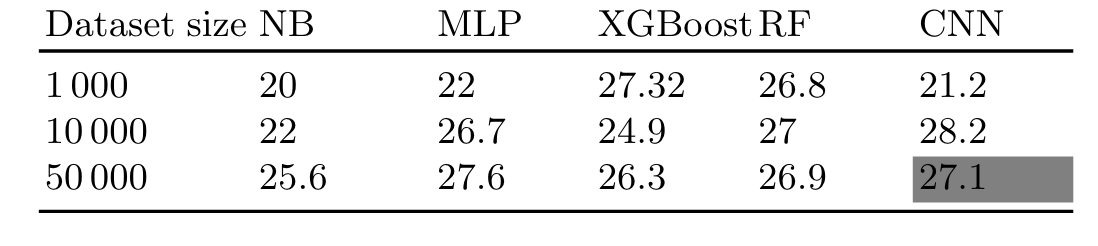
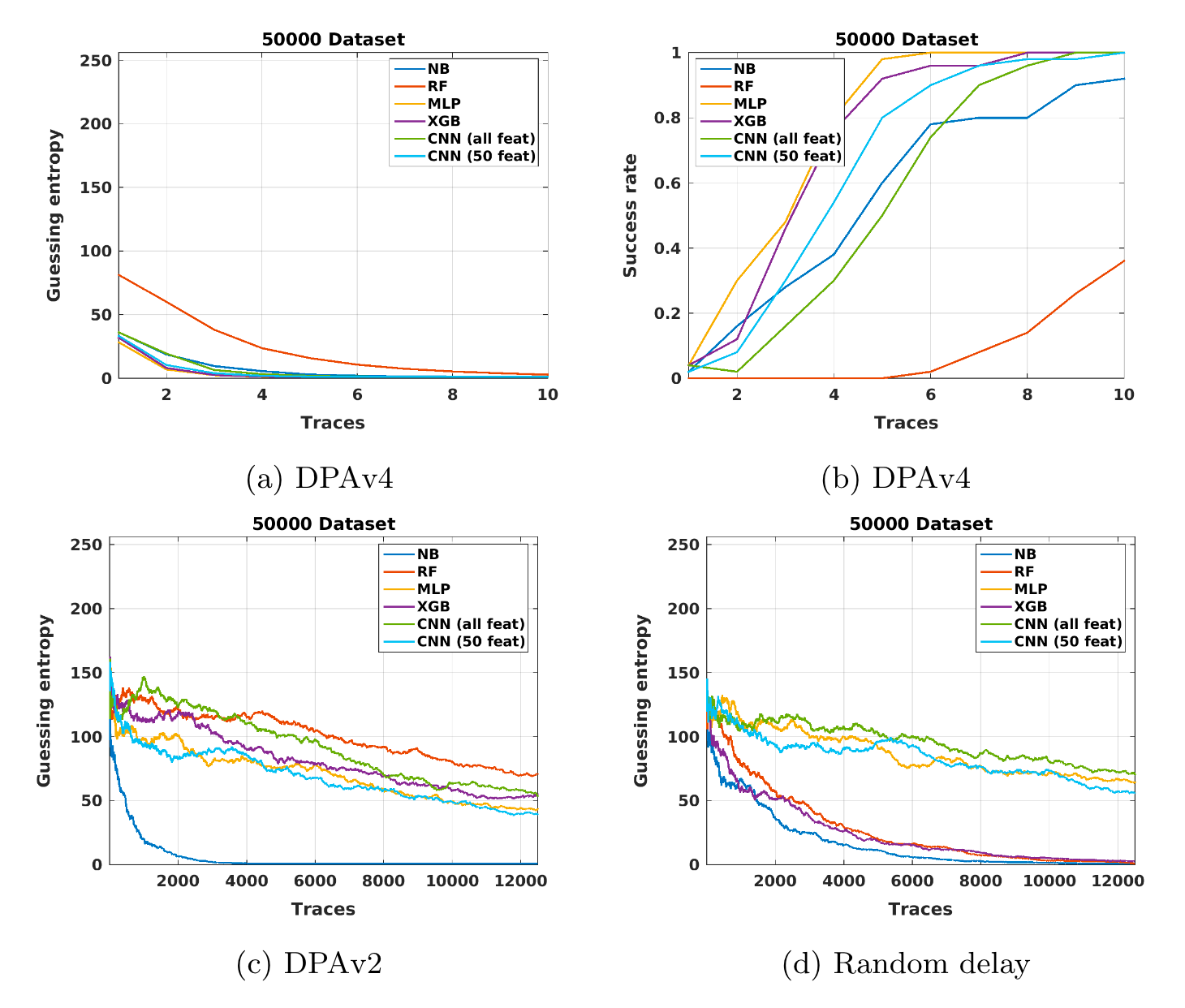
总结
作者主要是针对不同的数据集、模型做了系统的实验,给出结论:
- 仅增加能量迹条数或者特征数量不能保证性能有所提高,(特征数量只能连续添加, 不可能一直取信噪比最高的点否则在随机时延或时钟抖动数据集上模型效果会很差。
- 作者发现噪声与数据不平衡更影响CNN的性能。
- 作者发现CNN相较于其他机器学习模型训练开销更大,这个在超参搜索字典规模就可以看出来。
- 在不同的数据集上CNN模型的超参数需要重新训练,这样更会加剧训练开销。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 全世界的面我都吃一遍!
评论