
文献阅读笔记-The Best of Two Worlds: Deep Learning-assisted Template Attack
文章信息
- 作者:Lichao Wu, Guilherme Perin and Stjepan Picek
- 单位:Radboud University, The Netherlands; Delft University of Technology, The Netherlands
- 出处:IACR Transactions on Cryptographic Hardware and Embedded Systems
- 标题:The Best of Two Worlds: Deep Learning-assisted Template Attack
最近开题,开完无缝衔接流感,服啦!
文章内容
作者提出了基于相似性学习的特征提取方法, 使用三元组模型来实现;提出一种新的mertic来提高提取的特征质量
相似性学习(Similarity Learning)
相似性学习属于监督学习,其目的是为了通过训练来计算两实体之间的相似性,可以通过选择三元组模型来完成该任务。
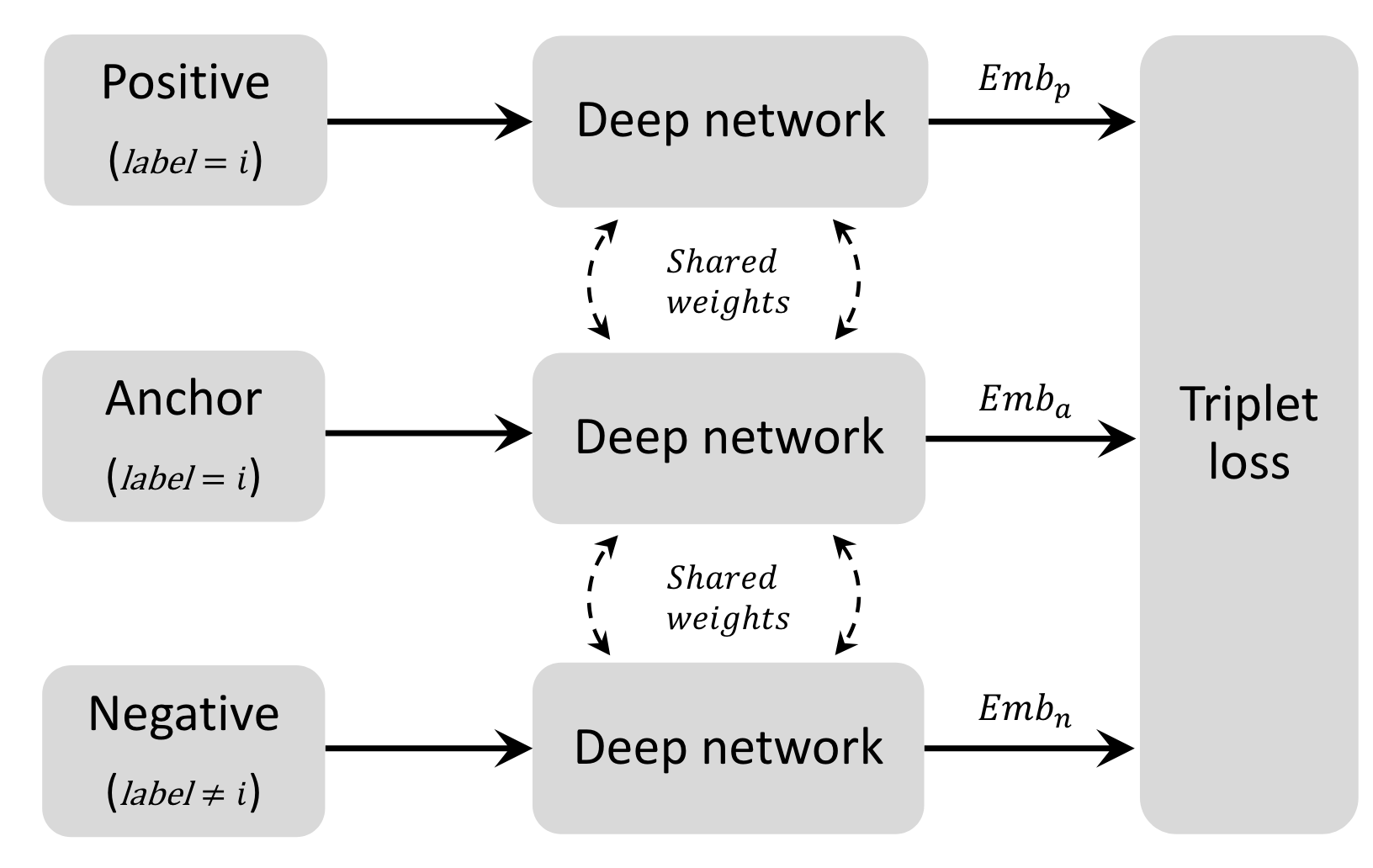
三元组
三元组由三种样本进行输入:正样本、负样本和锚点样本。其中正样本Positive与锚点样本Anchor具有相同的标签,
- 损失函数
d表示特征向量之间的欧氏距离,表示锚点,表示正样本,表示负样本, 是阈值用来控制正负样本之间的距离。
三元组分为三类,网络结构如图1所示,本文作者将设置为0.4:
| 类别 | 关系 |
|---|---|
| 正样本三元组 | 正负样本距离足够大 (>m),此时loss = 0,网络不再更新 |
| 负样本三元组 | 负样本与锚点的距离比正样本更近,此时loss>0, 网络继续更新 |
| 中等样本三元组 | 负样本到锚点距离虽然大于正样本到锚点的,但是没要大于阈值m,此时loss仍然大于0,网络继续更新 |
基于混合距离的三元组损失
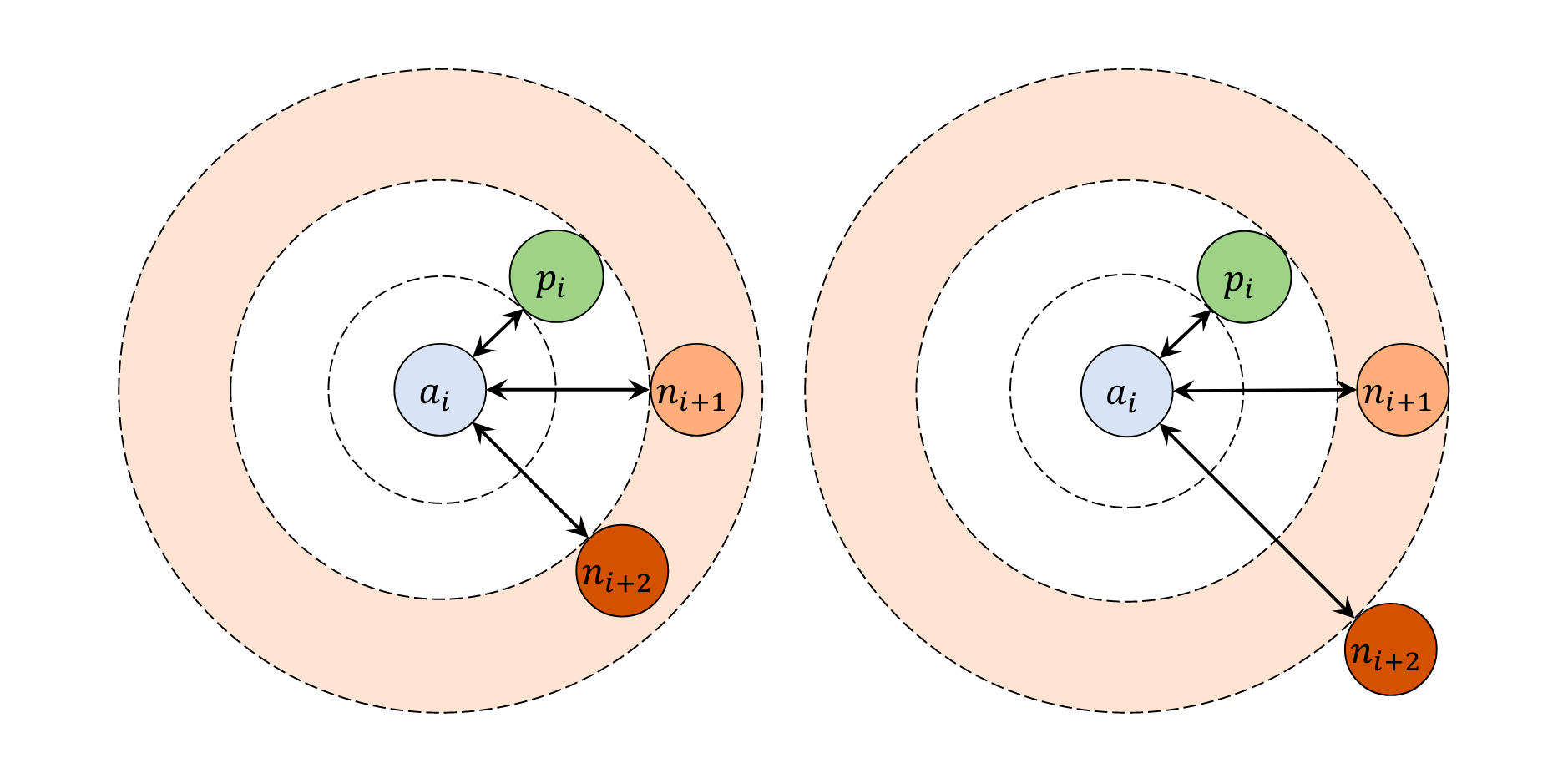
原始三元组方案忽略了负样本中的标签多样性,即对具有C个类别的数据集,负样本包含C-1个类别,作者认为如果在中等样本三元组中采用负样本的标签信息来寻找最接近锚点的负样本点,包含这种距离进的负样本点会促使模型学习效率会更好,分类性能提升更大。
虽然在CV领域不能通过标签来判断负样本点与锚点的相似性,但是侧信道攻击中是可以的(相似的标签可能是相似的泄漏点导致的),由此作者给出了基于混合距离的三元组损失函数如图2,其中 表示欧氏距离的平方,表示对应标签,表示标签归一化后的欧氏距离,
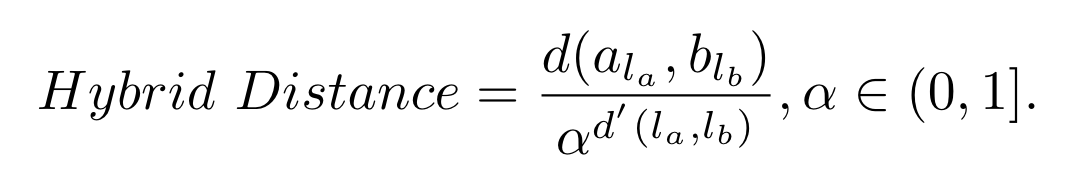
图三展示了在基于中等样本三元组情况下,欧氏距离与混合距离三元组损失的区别,即相较于传统欧氏距离,混合距离(右图)将不考虑,只在上学习。
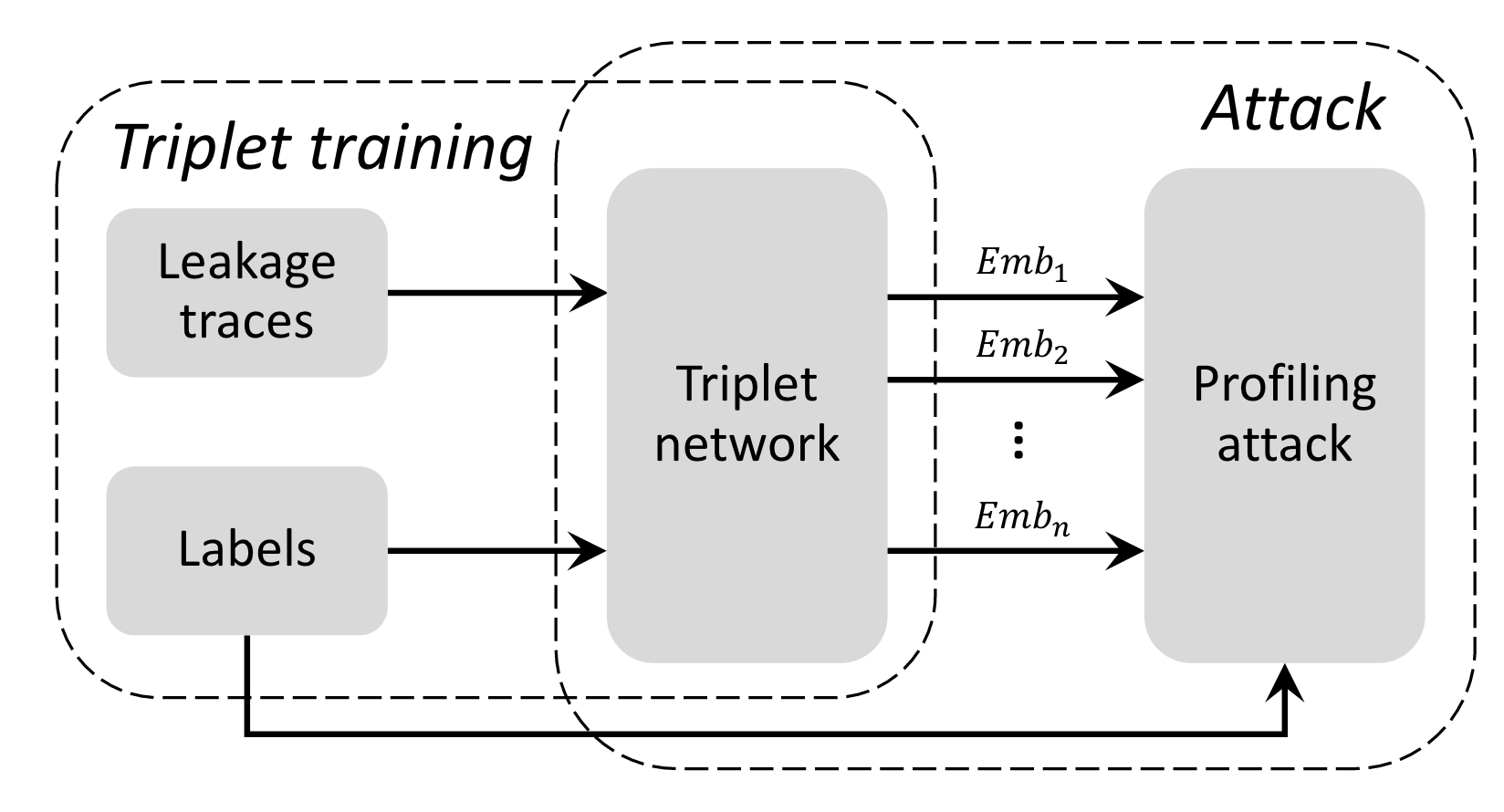
攻击步骤
- 训练三元组网络,获取Embeddings
- 使用训练好的Embeddings来完成攻击
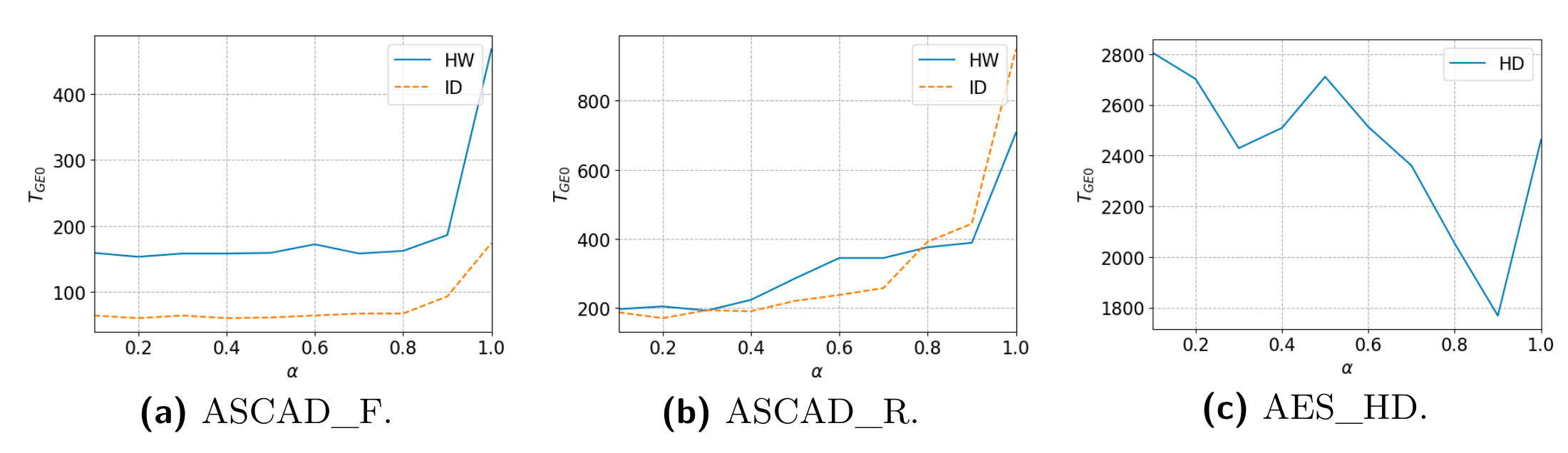
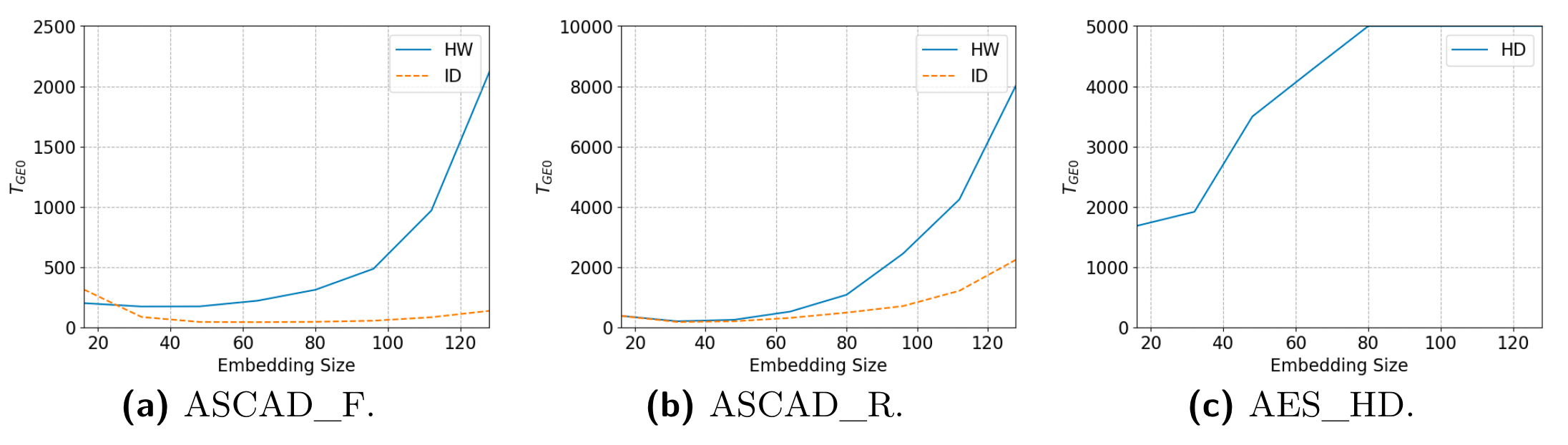
实验结果

这里是HW/ID两个泄露模型的猜测熵



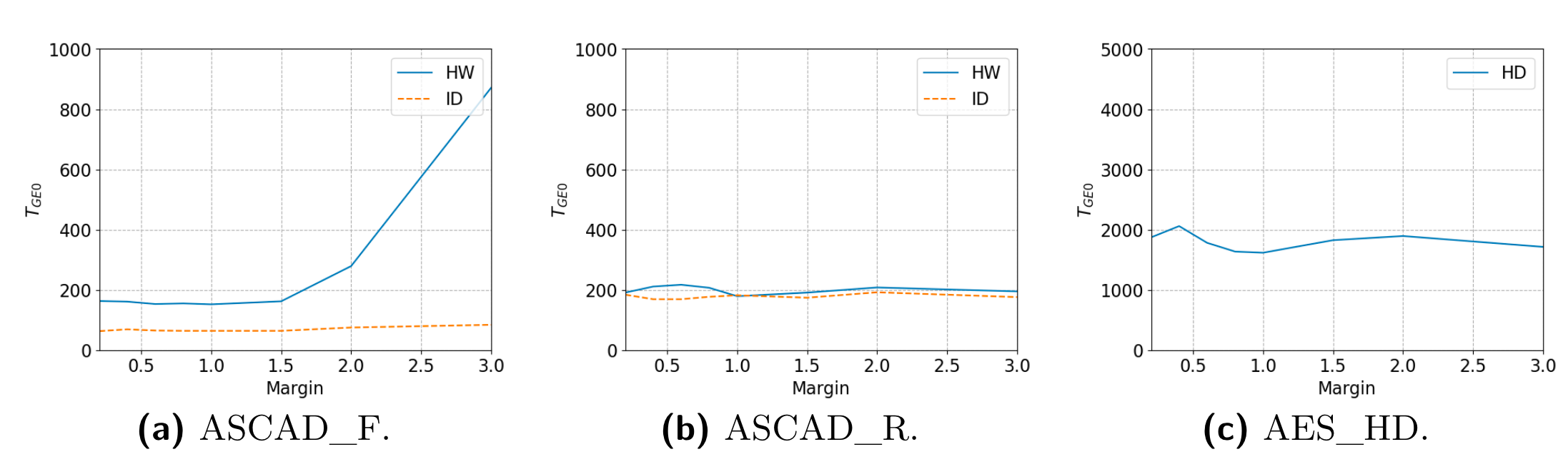
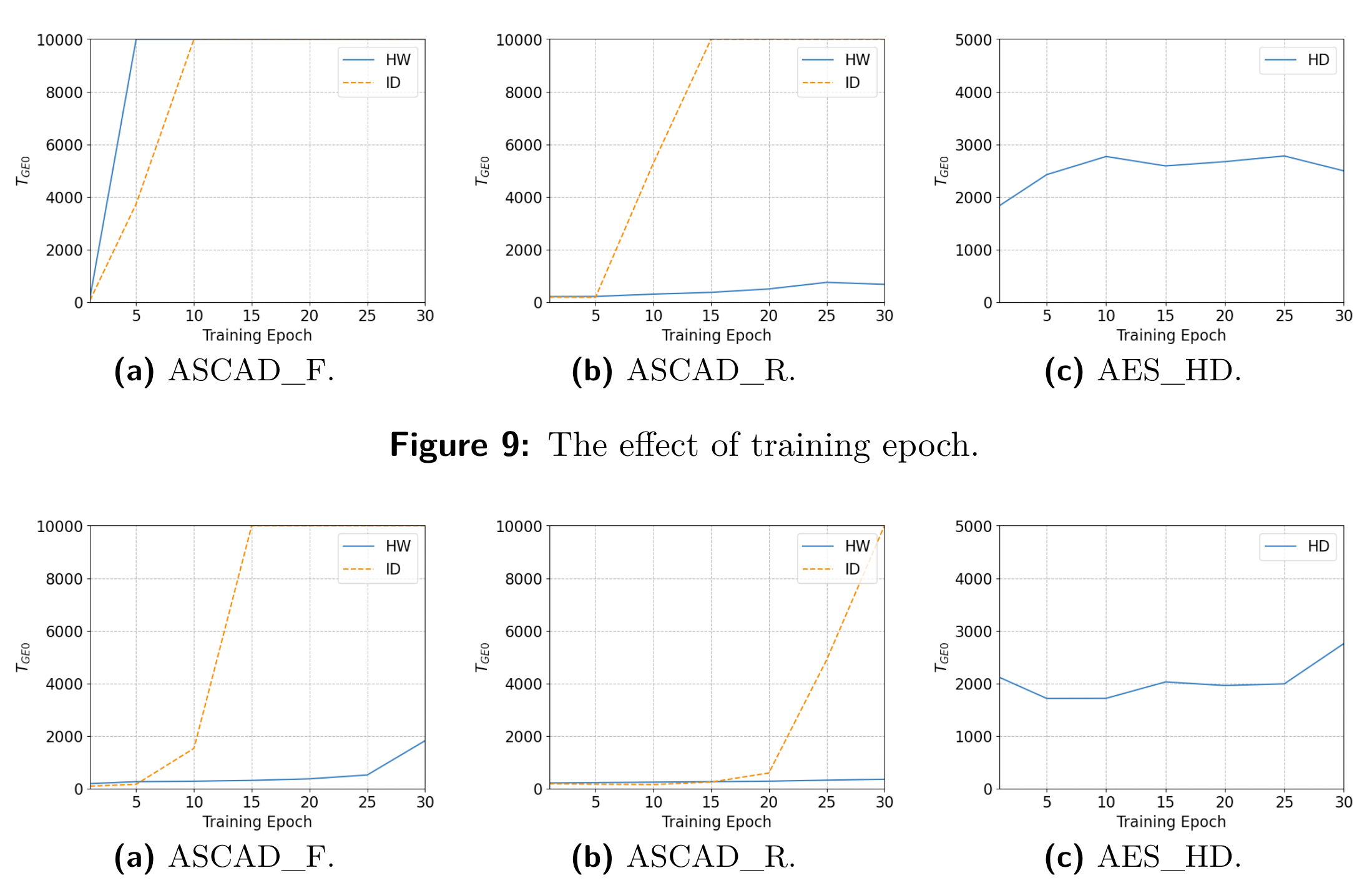
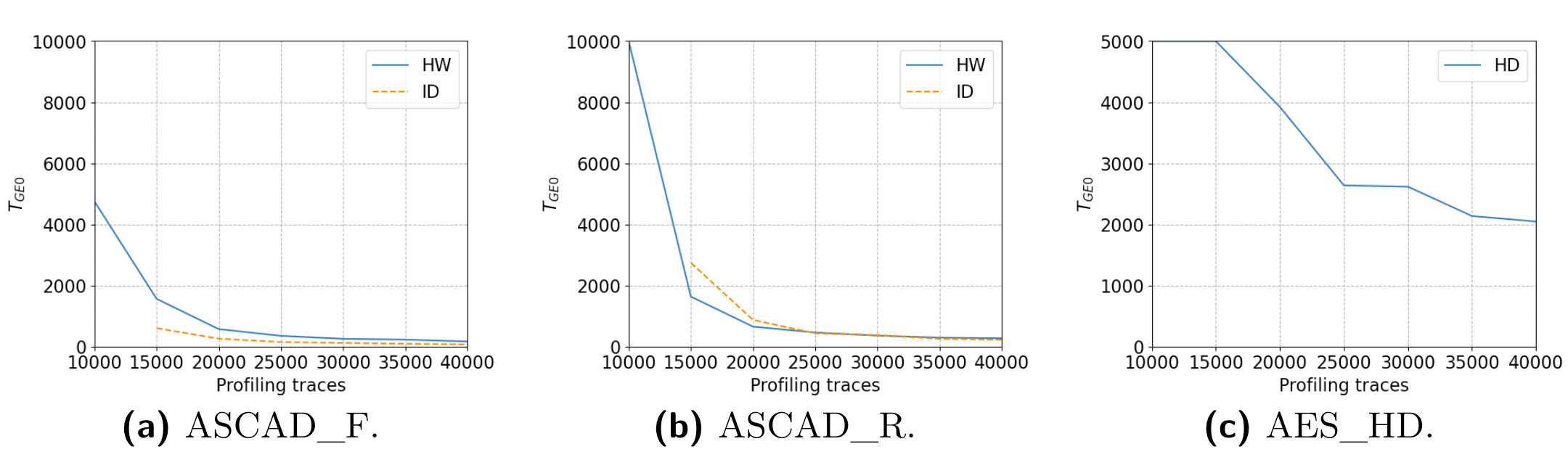
验证超参对收敛到0所需要的能量迹数量的影响
总结
作者基于原始三元组模型提出了一个新的基于混合距离的三元组模型,后续可以拼接到其他需要对抗时钟抖动等下游任务中。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 全世界的面我都吃一遍!
评论