写在前面
Kaggle只是迫不得已,真要学害得是我CTF!
EDA(Exploratory Data Analysis)
加载数据
在实际环境中,training data一般都有许多列,并不是所有的特征都会对最终的target有影响(影响因子较小甚至可以忽略),有的特征还存在负影响或者None值,此时需要对所有特征进行过滤或者修改。
Pandas
read_csv
读取csv文件
1
2
| path = bulabula
data = pd.read_csv(path)
|
columns
输出如下,将每列的name打印出来(例子
1
2
3
4
5
| Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount'],
dtype='object')
|
针对缺失值的行
dropna
1
2
3
4
5
6
7
8
| data.dropna(axis=0)
'''
将data中某列为Na的行删掉
例如:
|a|Na| |b|123|
---->
|b|123|
'''
|
展示列属性
1
2
| for col in data.columns:
print(col, data[col].dtype)
|
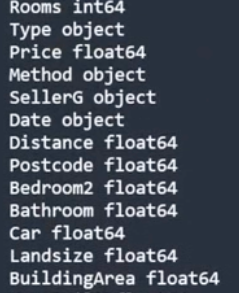
展示某列
1
2
3
4
| data.Suburb
data['Suburb']
data[['Suburb', 'Address', 'Rooms']]
|
describe
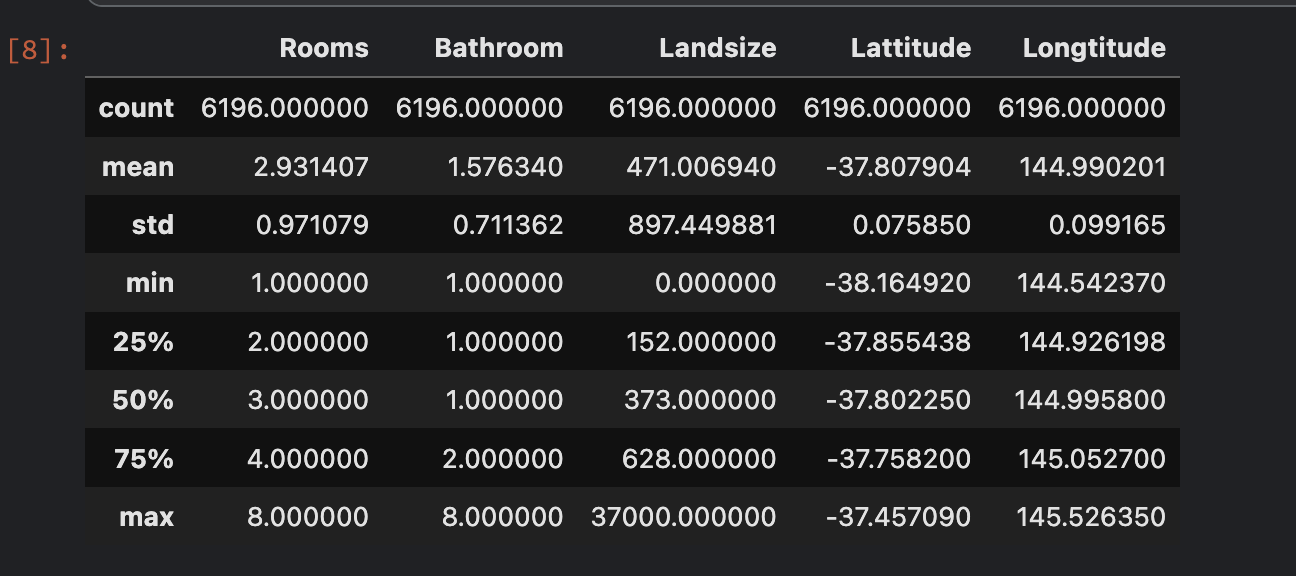
Missing Value
检查是否为Nan
1
| data['列名'].isnull().any True有Nan值,False无
|
取平均
1
2
| 在该列为连续型随机变量时,可以考虑直接拿中间值
计算该列所有值,取平均数填入缺失值
|
取最大频次
特殊值法
SimpleImputer
处理无效值api
1
2
3
| from sklearn.impute import SimpleImputer
my_imputer = SimpleImputer()
my_imputer.fit_transform(x_train)
|
Model
决策树 DecisionTreeRegressor
