数据集
| 名称 |
内容 |
| ASCAD |
60 000条能量迹, 700个特征 |
| AES_HD |
500 000条能量迹, 1250个特征 |
| AES_RD |
50 000条能量迹, 3500个特征 |
数据预处理
由于本论文中作者在每条能量迹都打上八个标签,因此要把原来的label划分为8bit,写了个简单的poc。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| in_file = h5py.File('../yourdatasets/ASCAD.h5', "r")
X_profiling = np.array(in_file['Profiling_traces/traces'], dtype=np.int8)
Y_profiling = np.array(in_file['Profiling_traces/labels'])
new_y_profiling = []
for i in range(len(Y_profiling)):
bin_y = f"{Y_profiling[i]:08b}"
bin_y = list(bin_y)
bin_y = list(map(float, bin_y))
new_y_profiling.append(bin_y)
new_y_profiling = np.reshape(new_y_profiling, (len(new_y_profiling), -1))
X_attack = np.array(in_file['Attack_traces/traces'], dtype=np.int8)
Y_attack = np.array(in_file['Attack_traces/labels'])
print(type(Y_attack[0]))
new_y_attack = []
for i in range(len(Y_attack)):
bin_y = f"{Y_attack[i]:08b}"
bin_y = list(bin_y)
bin_y = list(map(float, bin_y))
new_y_attack.append(bin_y)
new_y_attack = np.reshape(new_y_attack, (len(new_y_attack), -1))
|
神经网络架构
目前还是不会用api来写,先将就一下一步到底
ASCAD Nmax=0

代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| data_input = keras.layers.Input(shape=(700, 1))
output_left = layers.Conv1D(4, 1, activation='selu', padding='same')(data_input)
output_middle = layers.Conv1D(4, 7, activation='selu', padding='same')(data_input)
output_right = layers.Conv1D(4, 11, activation='selu', padding='same')(data_input)
concatenated_output = keras.layers.concatenate([output_left, output_middle, output_right])
conv_1 = keras.layers.Conv1D(4, 1, activation='selu')(concatenated_output)
bn_1 = keras.layers.BatchNormalization()(conv_1)
ave_pool = keras.layers.AvgPool1D(2, 2)(bn_1)
flatten = keras.layers.Flatten()(ave_pool)
fc_1 = keras.layers.Dense(10, activation='selu')(flatten)
fc_2 = keras.layers.Dense(10, activation='selu')(fc_1)
fc_3 = keras.layers.Dense(8, activation='sigmoid')(fc_2)
model = Model(inputs=data_input, outputs=fc_3)
|
这里output_left、output_middle、output_right分别代表了大小为1、7、11的卷积核,个数都为4,在经过一个连接层concatenate将得到的结果全部拼接起来,这里可以看出来大小为1的卷积核确实没起什么作用,既没有扩大感受野也没有起到减少复杂度的作用,后边就是正常的四个大小为1的卷积核,这里的作用确实是在BN层之前减少了计算的复杂度,(在这里测试了一下去掉这四个卷积盒后模型的复杂度为4w+,而加上之后为14364),之后就是正常的展平全连接,只是在最后将softmax函数改为sigmoid。
模型summary如图2所示。
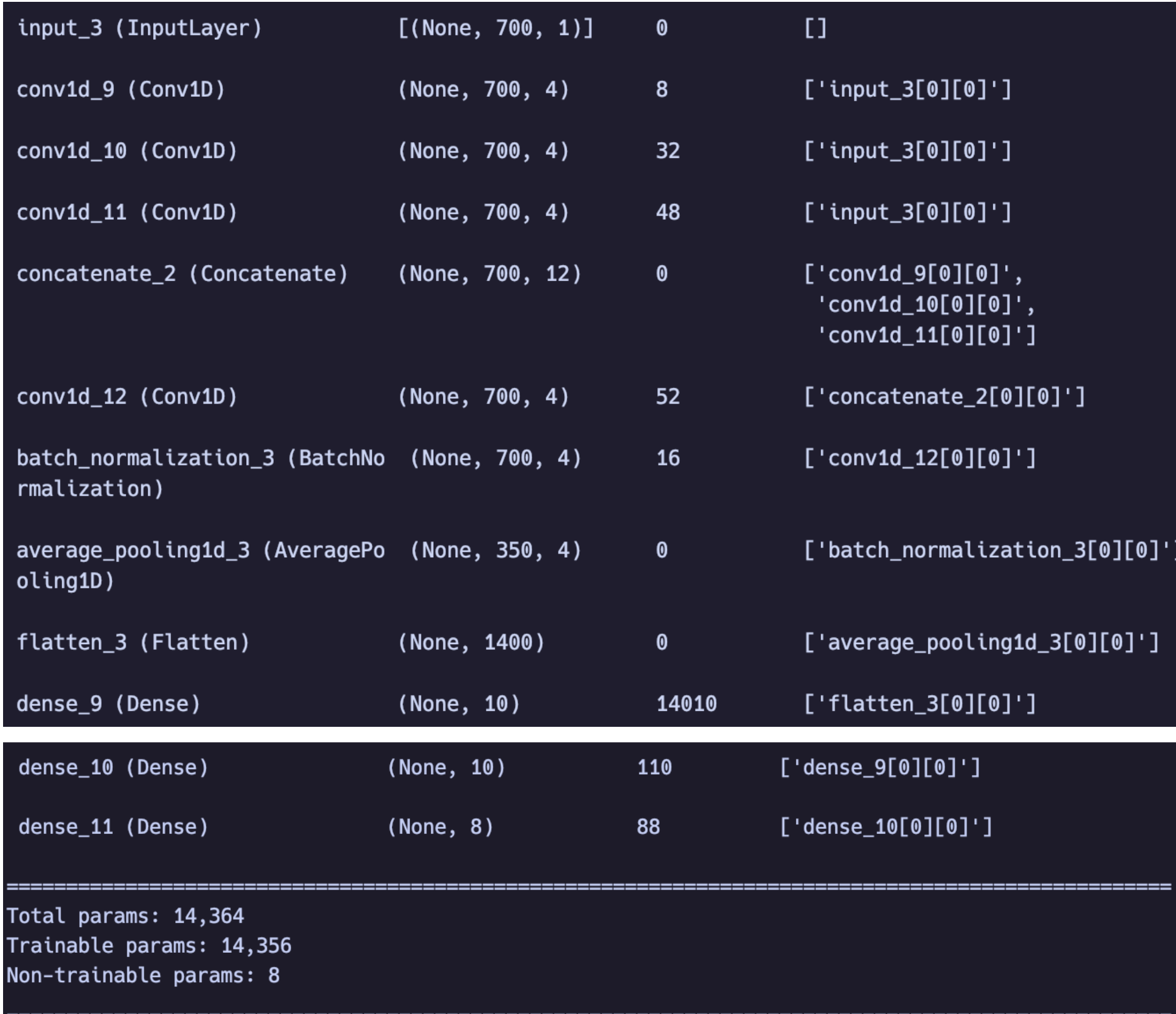
**优化器(**opt)采用adamax(Adam也可以, 作者这里没有说用哪个,我用了俩效果相差不大), 学习率(lr)0.005,loss选择二元交叉熵,epochs=100,batch_size=256
训练代码如下:
1
2
3
| model.compile(optimizer=keras.optimizers.Adamax(0.005) , loss=tf.keras.losses.BinaryCrossentropy(), metrics=['accuracy'])
history = model.fit(X_profiling, new_y_profiling, epochs=100, batch_size=256, verbose=1, validation_split=0.2)
|
测试代码如下:
1
| test_loss, test_accuracy = model.evaluate(X_attack, new_y_attack, verbose=2)
|
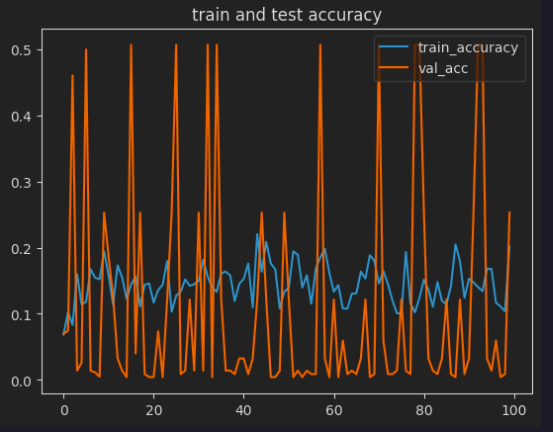
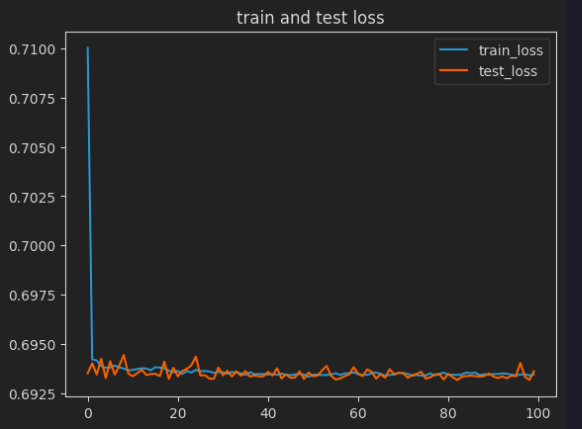
成功率以及损失如图3、图4所示,暂时应该是没有复现成功。
汇总
其实在复现的时候发现,自己的数据跟作者的老是对不上号,猜测可能是数据预处理或者优化器选的不是特别好,但最让我不解的是复现的模型复杂度有的跟作者的相同,但是有的少了1k,感觉是padding或者哪里小细节有问题,模型的代码全部传到github上了链接

