
文献阅读笔记-The Need for Speed: A Fast Guessing Entropy Calculation for Deep Learning-Based SCA
文章信息
-
作者:Guilherme Perin, Lichao Wu and Stjepan Picek
-
单位:Leiden Institute of Advanced Computer Science (LIACS), Leiden University, Niels Bohrweg 1, 2333 CA Leiden, The Netherlands;Faculty of Electrical Engineering, Mathematics & Computer Science, Delft University of Technology, Mekelweg 5, 2628 CD Delft, The Netherlands; Digital Security Group, Radboud University, Houtlaan 4, 6525 XZ Nijmegen, The Netherlands
-
出处:algorithms
-
标题:The Need for Speed: A Fast Guessing Entropy Calculation for Deep Learning-Based SCA
-
日期:2023年2月23日
背景
目前,侧信道攻击研究者们为了缩短训练所需时长,通常采用减小模型容量或者缩小训练集等方法,但此类方法会影响模型的泛化性能以及可学习性。ES(early stopping)作为一种有效监控模型训练以及防止过拟合的方案,它通过监控模型的损失值来完成对模型性能的监控,而在侧信道攻击中,模型的性能与损失值并没有绝对的对应关系。猜测熵作为侧信道攻击常用评估方案,使用猜测熵来作为ES的指标是可行的,但是由于计算猜测熵所需的时间开销过大,因此在超参数搜索时往往会导致搜索时间过长,在极端的情况下是不可行的。
内容
相关工作
Zhang等人[1]提出了一种猜测熵估计算法GEEA,缩短了计算猜测熵的时间,Perin等人[2]利用互信息方法来检测模型训练在某个Epoch时的性能。
主要工作
在每个Epoch结束后快速计算一次猜测熵FGE,通过判断猜测熵在哪个epoch最小。

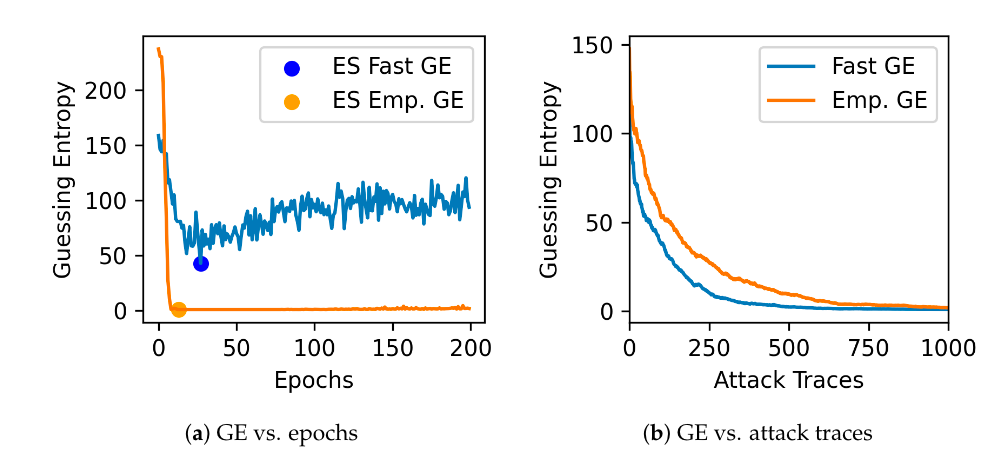
可以看到使用FGE作为指标的模型猜测熵收敛到1的速度更快。
FGE关键代码:
1 | # guessing entropy and success rate |
这里贴出来mlscat计算猜测熵源码
1 | def rank(predictions, num_traces, targets, key, interval=1): |
fast_ge在拿到predictions后直接对其做了映射,假设密钥$$k_i=1$$,对应的$$predictions_i[1]$$就是该密钥的预测概率,也就是位置与密钥值相等,在下方for循环中计算概率和时直接进行了累加,最后取排名均值。
代码看不出有什么区别,最后在传参处发现
1 | callback_fast_ge = Callback_EarlyStopping(number_of_traces_key_rank,X_validation_reshape[:validation_traces_fast],labels_key_hypothesis[:, :validation_traces_fast], correct_key, leakage_model) |
这里fastge传的是500个。
总体的方法就是这样,少量验证集完成猜测熵的快速计算。
接下来作者采用贝叶斯优化(BO)配合ES来完成超参数搜索,BO在keras库里有。
1 | script_bo_fge.py |
数据集
黑盒
| 名称 | 链接 |
|---|---|
| ASCAD | https://github.com/ANSSI-FR/ASCAD |
| CHESCTF 2018 | https://chesctf.riscure.com/2018/content?show=training |
模型架构
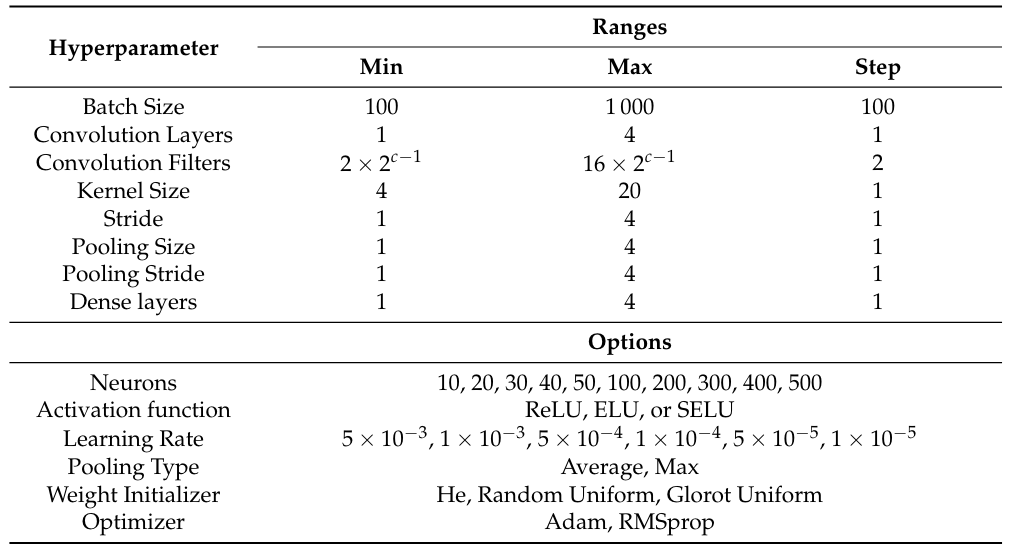
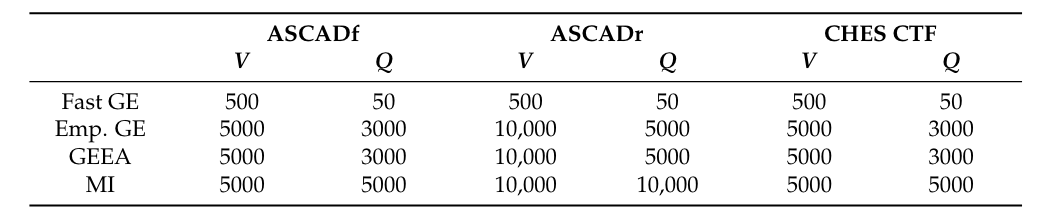
结果
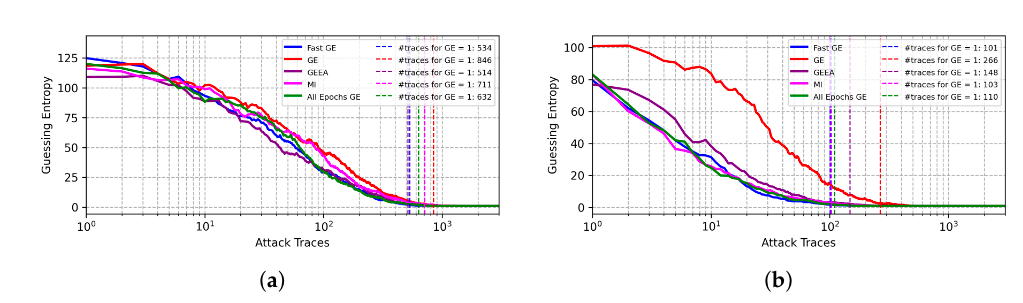
在ASCAD数据集上,采用身份泄露模型,FGE方案需要101条能量迹可将猜测熵收敛为1。
这里主要看BO+FGE,在身份泄露模型下,ASCADf数据集上需要72条即可收敛,汉明重量模型需要455条。
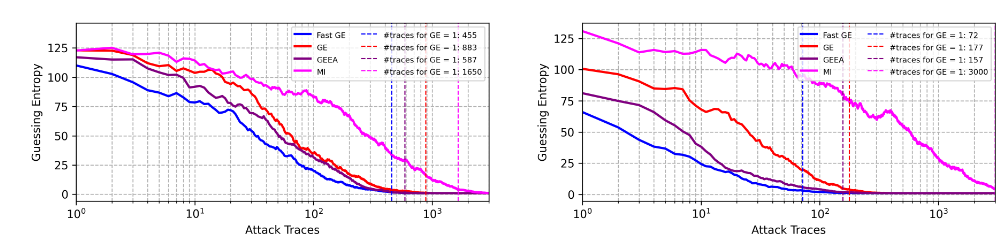
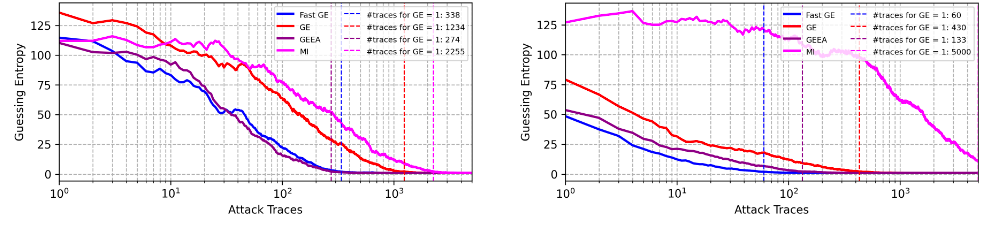
而在ASCADr数据集上,身份泄露模型仅需60条即可收敛。
Zhang, J.; Zheng, M.; Nan, J.; Hu, H.; Yu, N. A Novel Evaluation Metric for Deep Learning-Based Side Channel Analysis and Its Extended Application to Imbalanced Data. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020 , 2020 , 73–96 ↩︎
Perin, G.; Chmielewski, L.; Picek, S. Strength in Numbers: Improving Generalization with Ensembles in Machine Learning-based Profiled Side-channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020 , 2020 , 337–364 ↩︎