文献阅读笔记-CL-SCA: A Contrastive Learning Approach for Profiled Side-Channel Analysis
文章信息
-
作者:Annyu Liu1, An Wang 1, Shaofei Sun2 , Congming Wei1 , Yaoling Ding1 , Yongjuan Wang3 , and Liehuang Zhu1。
-
单位:
- School of Cyberspace Science and Technology, Beijing Institute of Technology, Beijing 100081, China
- School of Cyberspace Security, Beijing University of Posts and Telecommunications, Beijing 100876, China
- Institute of Cyberspace Security, Information Engineering University, Zhengzhou 450001, China
-
期刊: IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY (一区 TOP)
文章内容
食用之前可以先看一下A Simple Framework for Contrastive Learning of Visual Representations、Investigating the Benefits of Projection Head for Representation Learning这两篇文章
背景问题
传统基于深度学习的侧信道攻击(DL-SCA)方法主要关注点在能量迹与中间值标签之间的关联性,忽略了样本之间的相似性(这里类似的工作是标签相关性以及三元组),此外,由于传统的侧信道攻击方法与标签相关,在训练时,无法直接利用攻击集中的能量迹。
本文方法
作者提出了一种基于对比学习的侧信道攻击方法,解决了上述问题,基于无监督学习的模型,将两个标签相同的样本进行,此外,由于无需标签,可进一步将攻击的能量迹用作训练。
数据增强
为了满足对比学习需要相同标签能量迹这一需求,作者利用了下图三种数据增强方法(随机移位,随机裁切和随机降噪)。
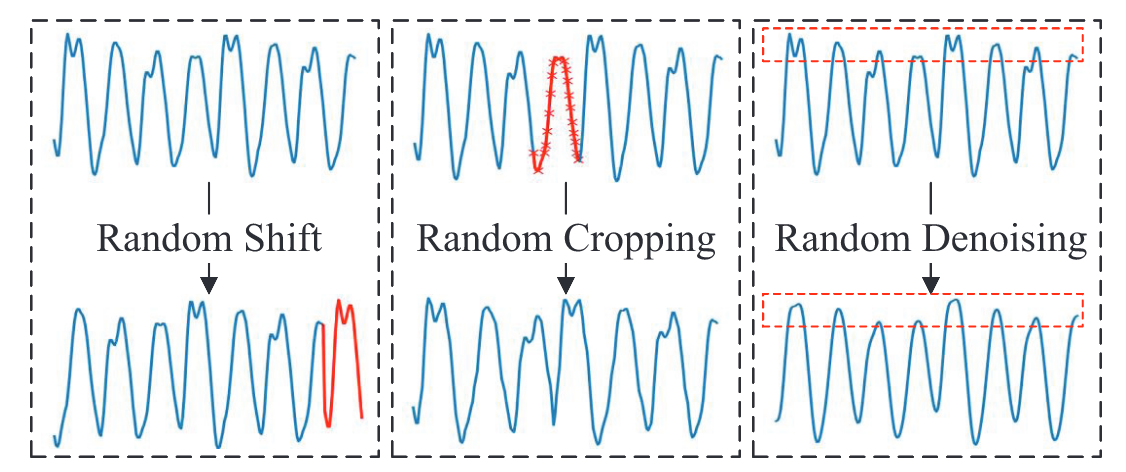
随机移位
该方法通过将能量迹向左或向右随机移位$n$个时间样本点,实现位移偏移,以此来完成能量迹的扩充。传统侧信道攻击在面对能量迹不对齐的情况时,在攻击实施之前需要先进行能量迹对齐操作,但由于深度学习模型(CNN 等)可以很好的应对这种不对齐的场景,以此来完成。假设最大可以移动$L_s$位,则针对每条能量迹,随机取$[-L_s,L_s]$之间的某一个数,使能量迹向左或向右偏移,具体如下所示(能量迹两端如果空白我一般直接填充Nan 值,但本人认为也可直接在能量迹两端裁剪最大随机窗口大小的能量迹段,之后取两端的数,亦可用其他方法) $$ l_s = \text{random}(-L_s,L_s) $$ 随机裁切
作者设置了 50% 的裁切概率,随机在能量迹上的随机位置切除长度为 $L_c$ 的能量迹段,在裁切过后,需要均匀拉长能量迹,使其恢复到原来的长度,裁切方法如下所示。 $$ p_c=\text{random}(0, L - L_c) $$ 随机降噪
这里还以为是随机加噪声,结果是取平均去噪,其实类似于平均池化的思想,具体实现如下所示。
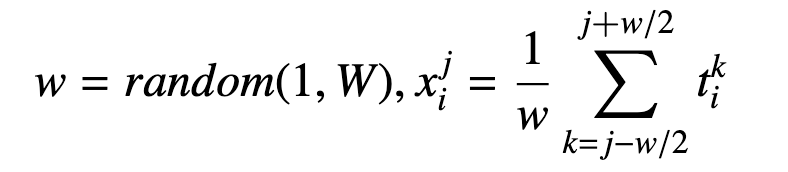
具体实现链接:Click Here
基于SIMCLR的侧信道攻击
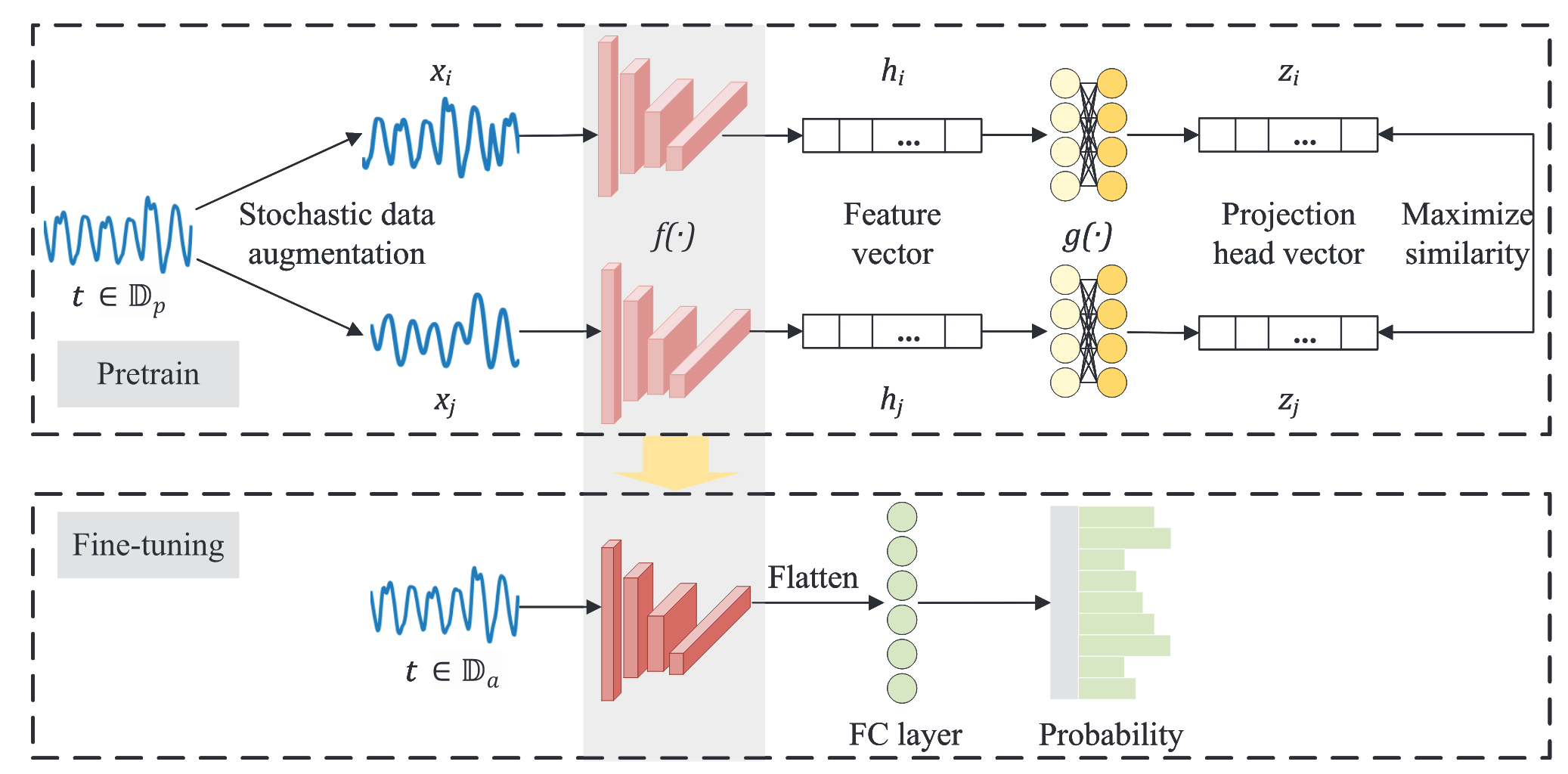
- 为了完成有效特征的提取,针对原始能量迹,首先从上述三种数据增强的方法中随机挑选两个生成新的能量迹$x_i, x_j$,此时,这两个能量迹的标签相同,通过最大化相似特征的方法来训练编码器$f(\cdot)$,从而完成有效特征的提取,这里的方法值得再思考一下,作者选择的是两种随机选择的数据增强方法。
- 经过编码器提取过后的特征$f(\cdot)$,转化为 Feature vector(Fv),之后通过投影头函数 Projection head $g(\cdot)$进一步完成特征的提取,学习更健壮的特征表示,这里作者用了两层 MLP 来组成这个头。(https://zhuanlan.zhihu.com/p/378953015)
- 训练自编码器,尽可能的将压缩后的特征更相似,这里与 SIMCLR 一样用的NT-Xent损失函数。
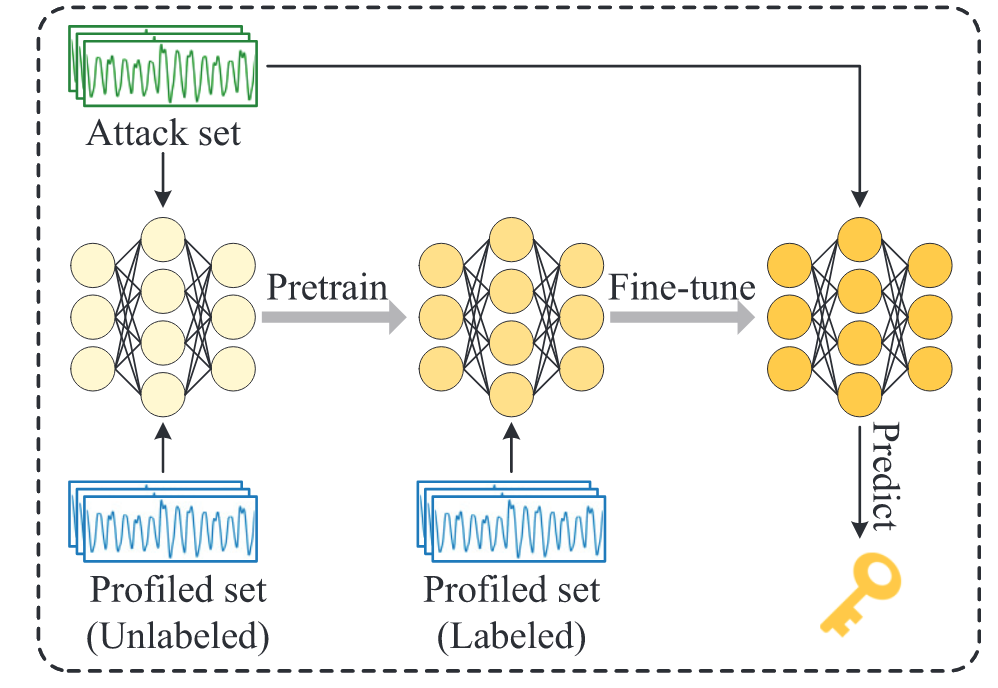
CL-SCA+
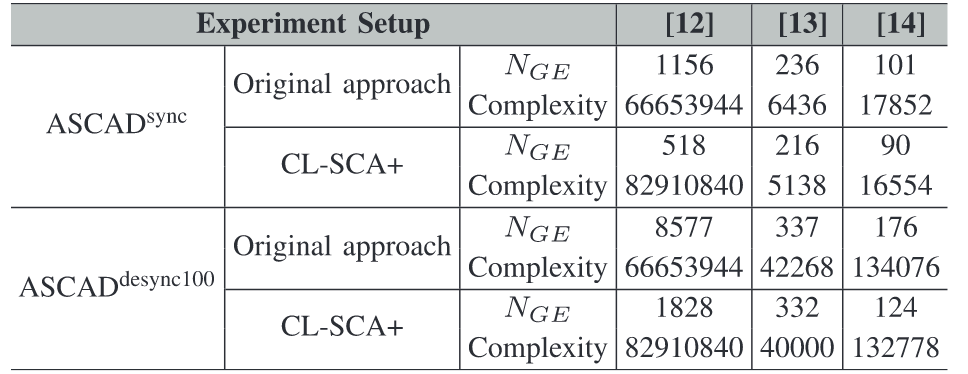
这里我认为是本篇文章的核心,前边的工作基本就是裁了 2020 年的 SIMCLR 工作过来,但这里引入攻击能量迹确实是一个比较亮眼的创新点,后续无监督模型都可以借鉴这种思想,用被攻击的能量迹进行训练。
与上一节不同,CL-SCA+的预训练模型中加入了训练集,之后再用带有标签的训练集进行 fine-tune,搜索到的最佳超参数组合:优化器:Adam;学习率:0.00001、损失函数:NT-Xent、损失函数中$\tau$偏置设置为 0.07,Epochs:200、Projection Head Output:128。
实验结果
数据集一共包括:ASCAD 以及作者自己采集的数据集共五个,这里效果推荐直接看论文(结果很重要,但不关键)
CL-SCA
ASCADf 和 ASCAD_desync100
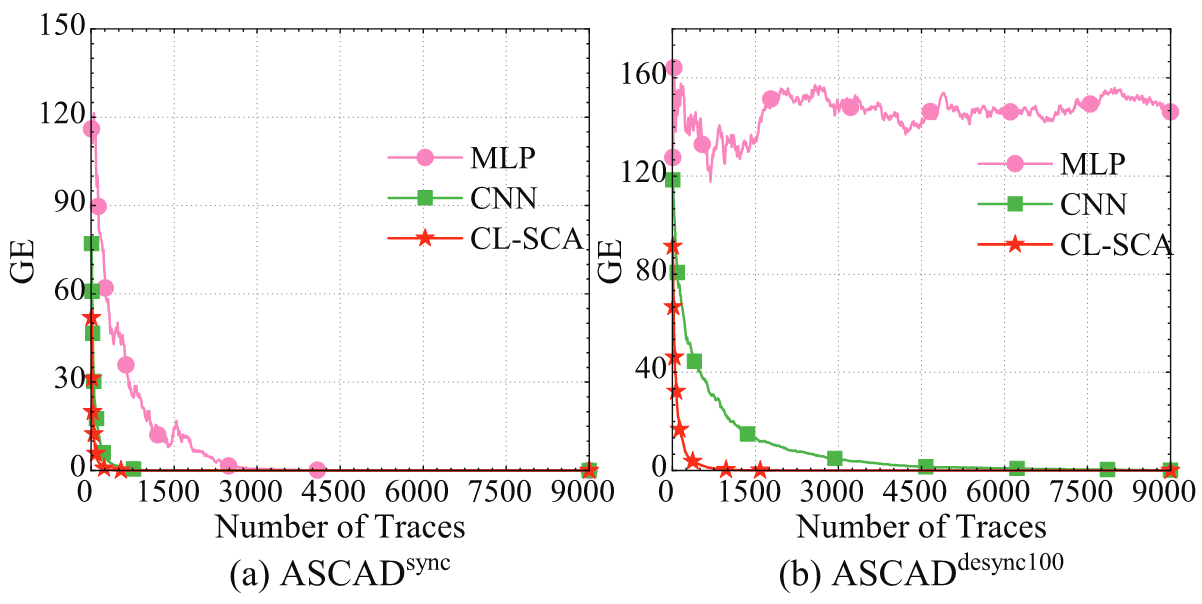
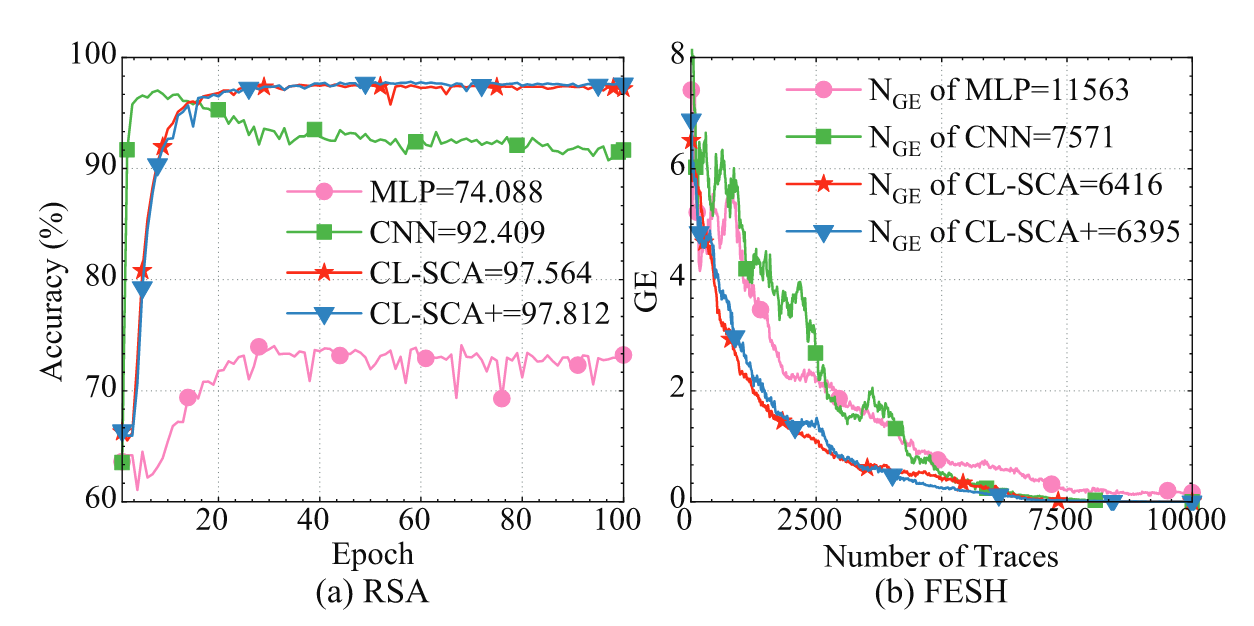
分析下图可知,相较于原来的 MLP 和 CNN 的工作,在对齐的能量迹上,CL-SCA 仅需 828 条能量迹即可完成密钥的恢复,在随机延迟窗口大小为 100 的数据集上,CL-SCA 仅需 2540 条能量迹完成密钥的恢复。
AES-SAKURA
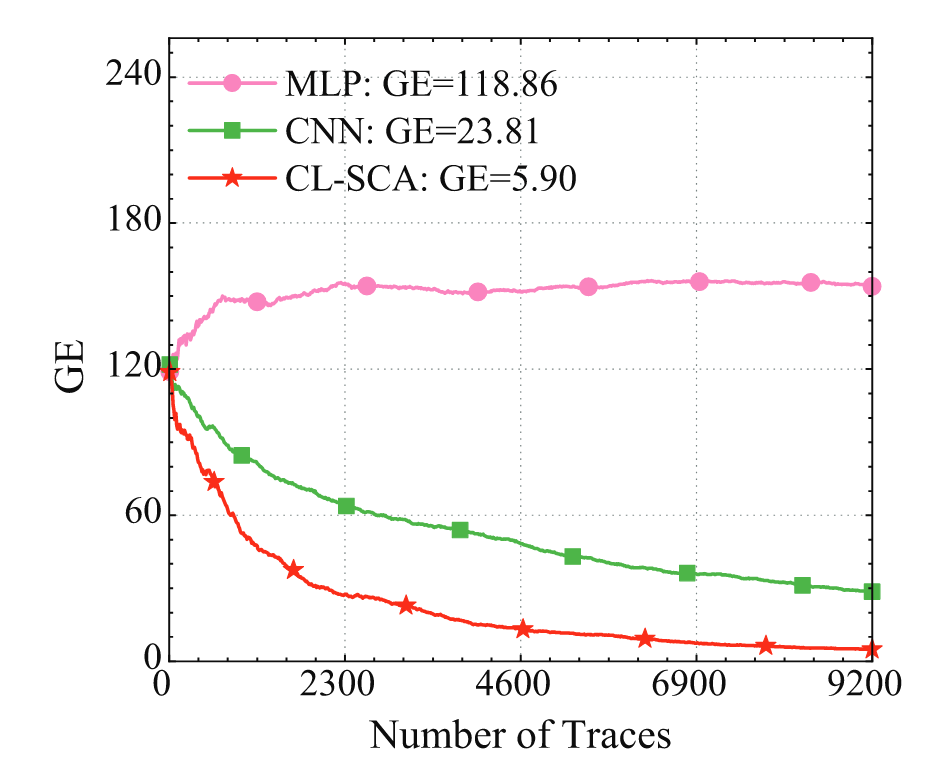
在自行采集的AES-SAKURA 数据集上,通过测试集中包含的10,000 条能量迹计算出来最后猜测熵为 5.9 ,尽管无法恢复密钥,但相较于其他两个方法,CL-SCA 仍然可以把猜测正确密钥的代价降到最低。
可解释性分析(凑工作量的好方法,可以以每层的梯度、注意力权重等来制图)
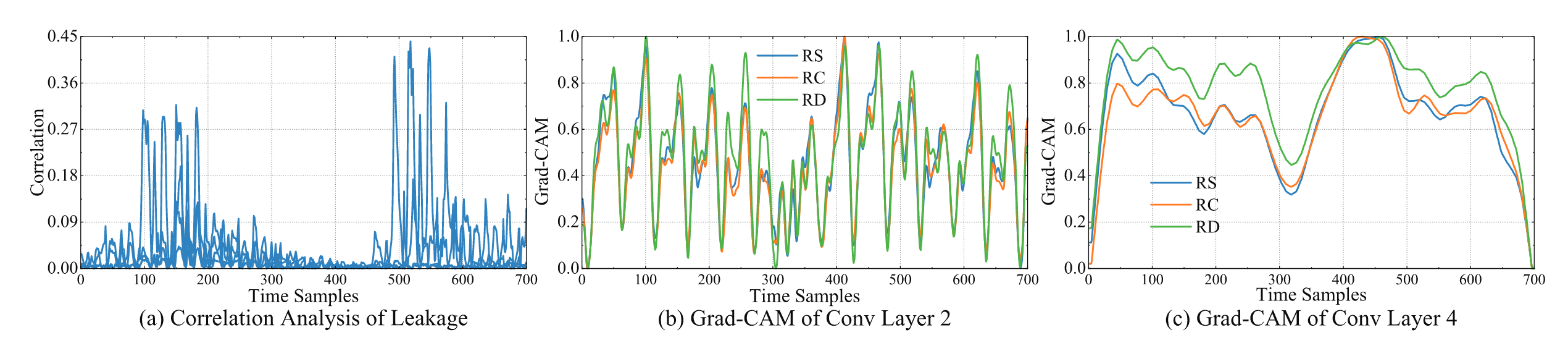
在 $ASCAD^{sync}$数据集上,分别展示能量迹对应的皮尔逊相关系数,第二个、第四个卷积层对应的梯度,对比图中(a)与(c)子图可知,模型在第四个卷积层关注到了高相关性的特征区间,这里作者说通过数据增强方法可以增强模型的特征提取能力,但我感觉图中好像少了一个无数据增强的梯度的对比,尽管在猜测熵结果上是可以展示出模型效果,但如果在文中说从图中看出加上数据增强方法要比不加好像有点主观(个人认为。
CL-SCA+
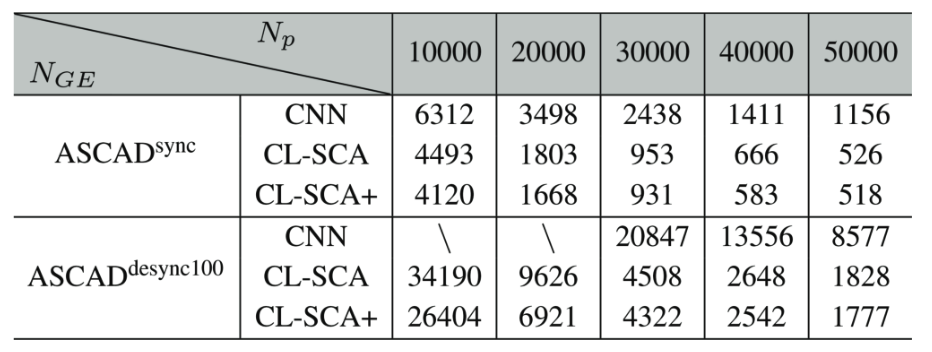
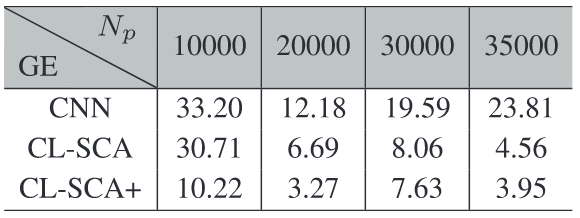
从结果上来看确实要比没有用到测试集的效果好。
总结
这篇文章的思路读下来比较明确,偏应用型的文章,主要将 SIMCLR 引入到侧信道攻击中,关键的创新点在于将测试集引入到训练阶段,这种方法使得模型恢复密钥所需的能量迹进一步有所减少,为后续无监督侧信道攻击给出了新的思路。
Related Content
- 模板攻击从入门到入土
- 旅行记录-长沙
- 侧信道攻击-信噪比
- 侧信道攻击-皮尔逊相关系数
- 文献阅读笔记-Label Correlation in Deep Learning-Based Side-Channel Analysis