
文献阅读笔记-Deep Learning based Side-Channel Attack-a New Profiling Methodology based on Multi-Label Classification
文章信息
-
作者: Houssem Maghrebi
-
单位: -
-
出处: eprint
-
标题: Deep Learning based Side-Channel Attack: a New Profiling Methodology based on Multi-Label Classification
文章内容
背景
目前基于深度学习的侧信道攻击(DLSCA)方法越来越多,经过相关研究,人们发现DLSCA针对于未对齐的能量迹攻击效果依旧较好,在训练以及攻击阶段,研究者以8bit为单位对密钥进行恢复,即针对AES的16字节密钥,需要对每个字节训练出一个模型,以此来挨个回复全部的密钥字节。重复的16次操作带来了较大的复杂度。
本文工作
作者提出的工作中,在保证了攻击效率的前提下,一个模型对应恢复密钥的两个字节,并且在某些情况下训练用时要比之前的方法训练的要快。
技术
侧信道攻击
侧信道攻击是一种通过收集硬件设备泄露的信息来对关键信息进行恢复的攻击方式,其中建模攻击在安全评估中扮演着较为重要的角色,攻击者通过在目标设备相同的副本上采集泄露的信息并在对信息进行分析后在被攻击设备上进行关键信息恢复的操作, 如图1所示。
CNN LSTM
工作细节
在文献[1]中已经给出了最大能一次恢复32bit密钥的证明,但是如果单次恢复32bit会在 建模和攻击阶段造成较大的时间复杂度以及攻击复杂度,在这里作者选了16bit作为单次恢复密钥的长度,(这里泄露评估先不写,没看),也就是说作者针对AES KEY的前两个字节进行恢复,将一个密钥的前两个byte作为一组标签, 或者两个不同的操作的输出值(泄露值)作为一组标签。
在大部分工作中,都采用来表示一条能量迹,和是明文和密钥的byte子集,在本文中,作者采用以下两种标记方法:
- N是密钥byte子集的个数
- 这里是中间泄露, N也就是对应NByte的密钥
由于有的时候密钥的不同字节会有相同的输出,也就是, 对此作者采用 也就是二者label值相隔一个256;同样,对于两中间值,有,对应 , 这里是输出的大小(单位bit), N是标签集的大小,
对于第一种标记方法最小的侧信道观测点也就是POI的数量是, 对于第二种方法最小数量为
对于AES算法,N在这里需要等于2,=8,对第一种标记方法,一组标签具体为,对于第二种标记方法,标签具体为。
这里也就是隔了2的(bit数)次方,这样俩都可以分开
方法
作者生成了L条能量迹,每条能量迹有八个时间样本点,用来对应输出俩S盒的值(), 这里Z0,Z1是由密钥对应的字节()来生成的, 对数据集的划分为8-1-1, 即8成的训练集,1成验证,1成测试。 这里需要回答一个问题,那八个时间样本点是指什么?
实验结果与对比分析
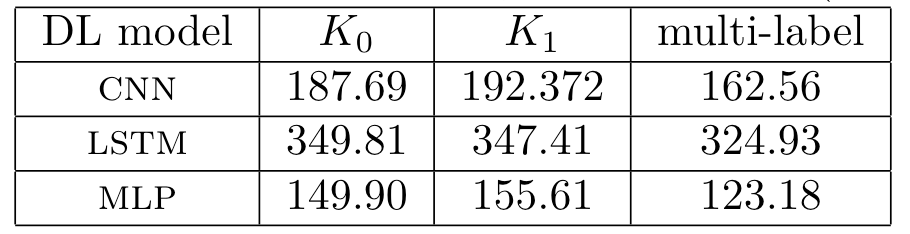
可以看到在图一不同模型中,单标签训练耗时总体上来说与多标签相差不大,也就是说增加恢复密钥的字节数量并没有确定增加训练时间。
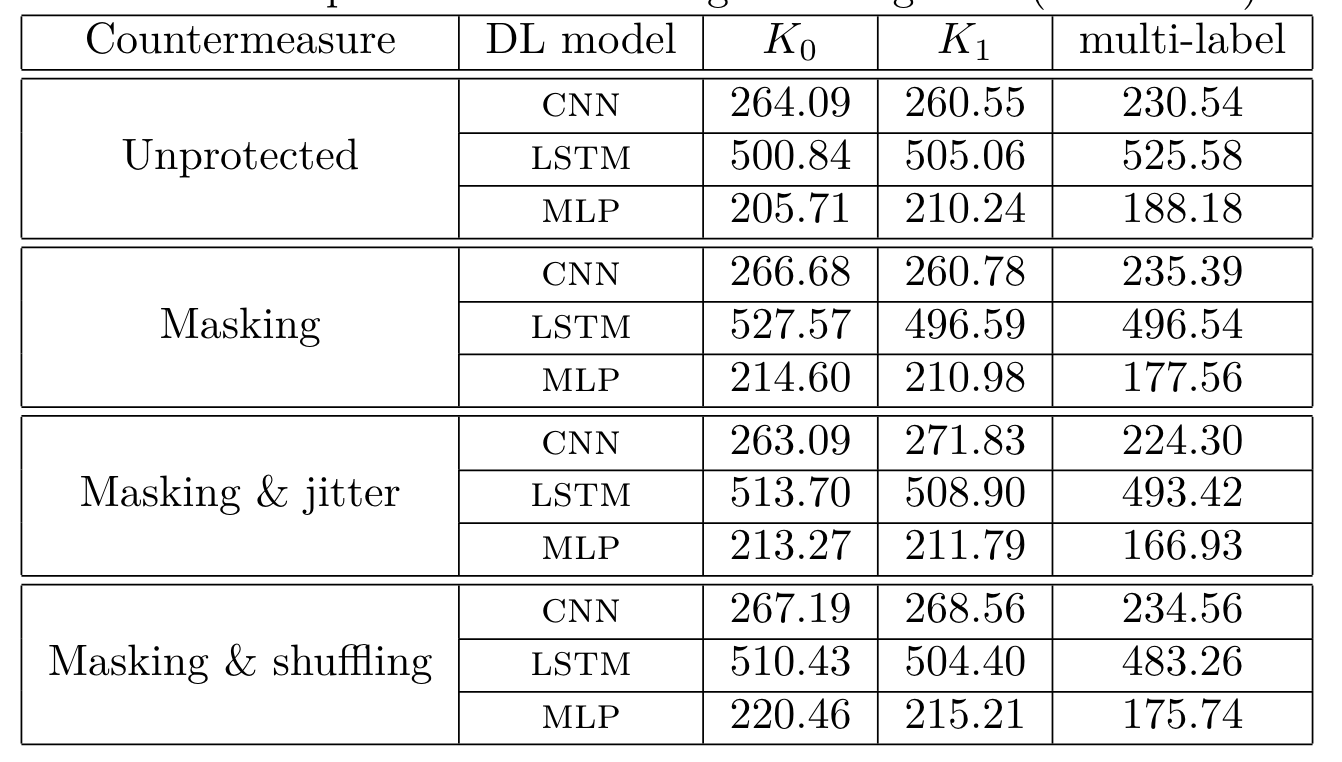
此外,作者又在ChipWhisperer平台上做了一些测试,选取8w条能量迹做训练,1w验证集,1w测试集,分别做了四组对照,1. 未做防护 2. 掩码 3. 掩码和时钟抖动 4.掩码和打乱, 抖动是随机将能量迹右移0-20的距离, 用来模拟未对齐的能量迹, 猜测熵收敛曲线如图2所示,训练耗时如图3所示,这里可以看出多字节的训练方法要比单字节的训练时间短。
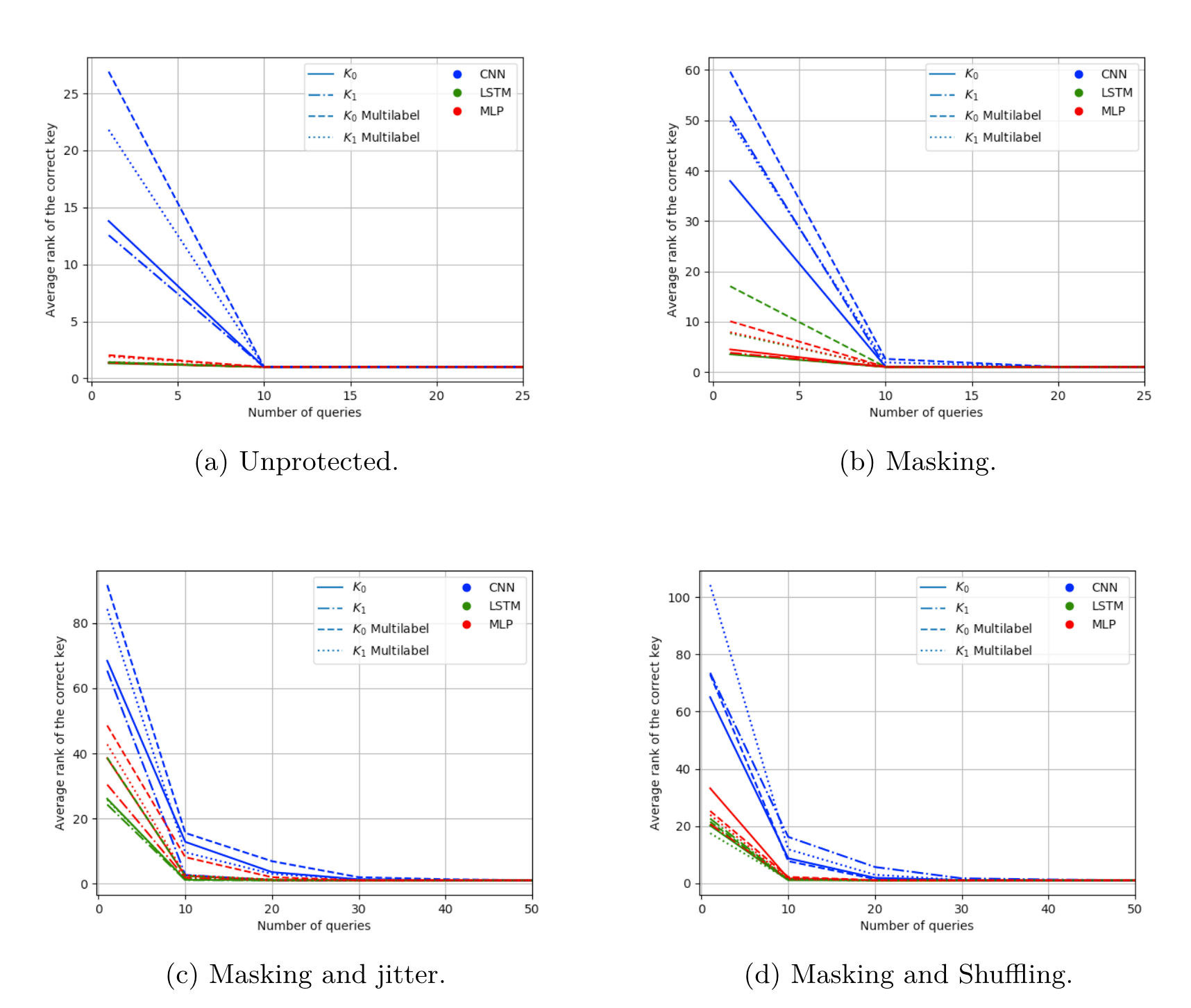
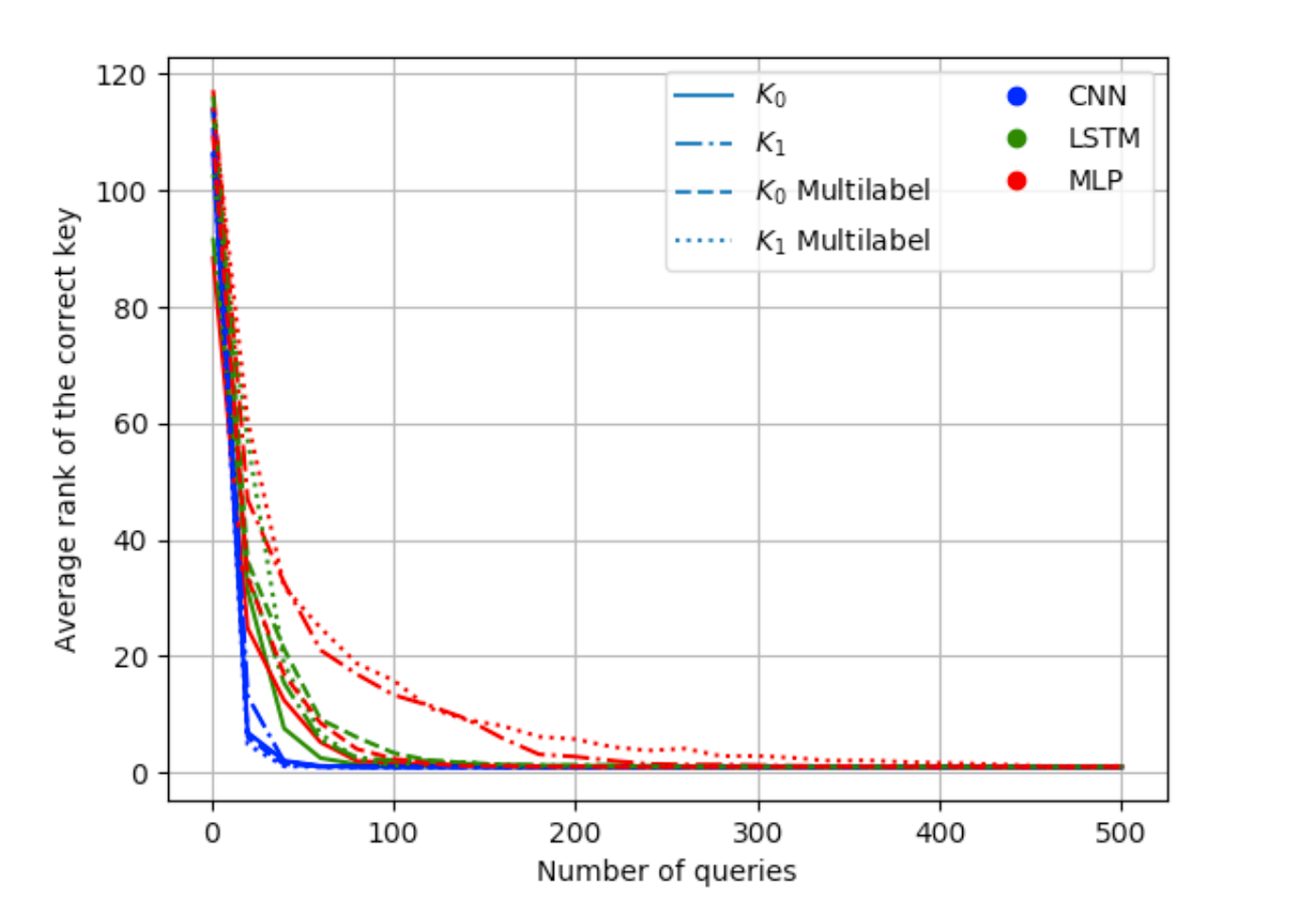
缩短了时间,是否能保证攻击的效果?图4可以看出最后的攻击结果是一致的,即多字节猜测熵收敛曲线与单字节曲线相匹配, 这里其实是效果稍微差一点,但确实收敛曲线的走势都是一样的,最后在100个epoch后排名相差不大。
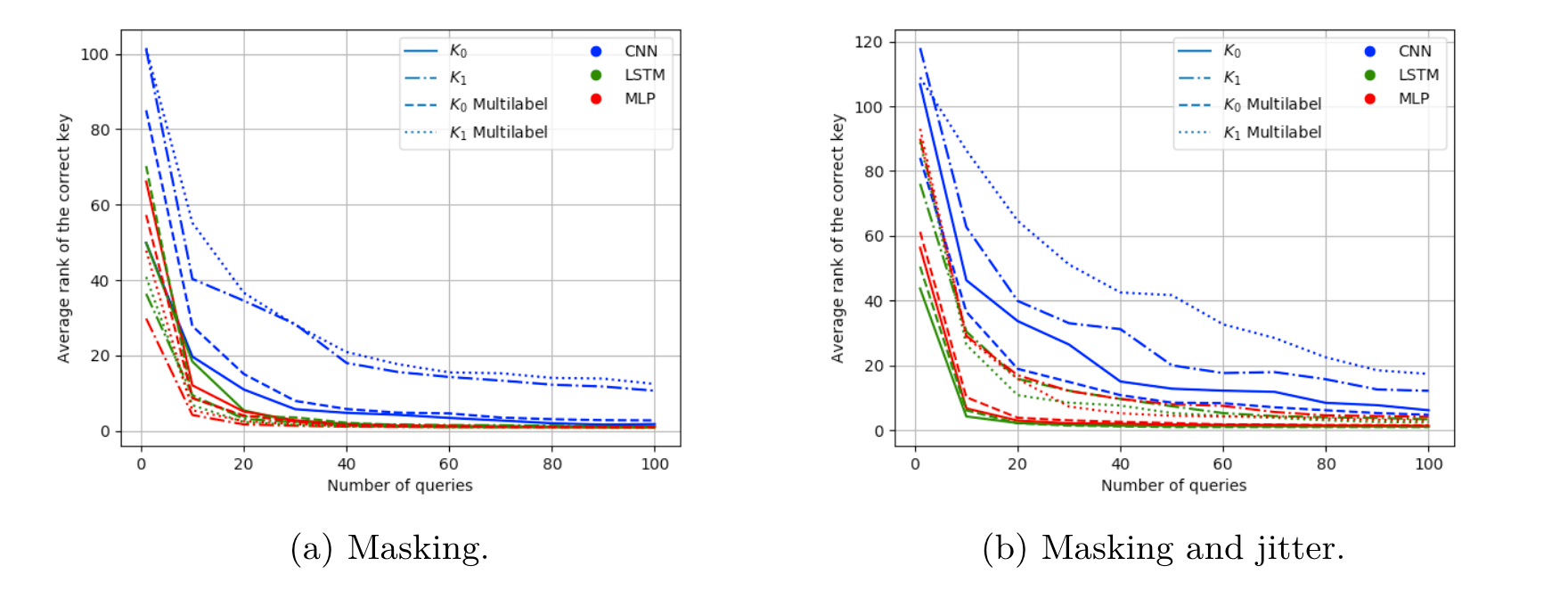
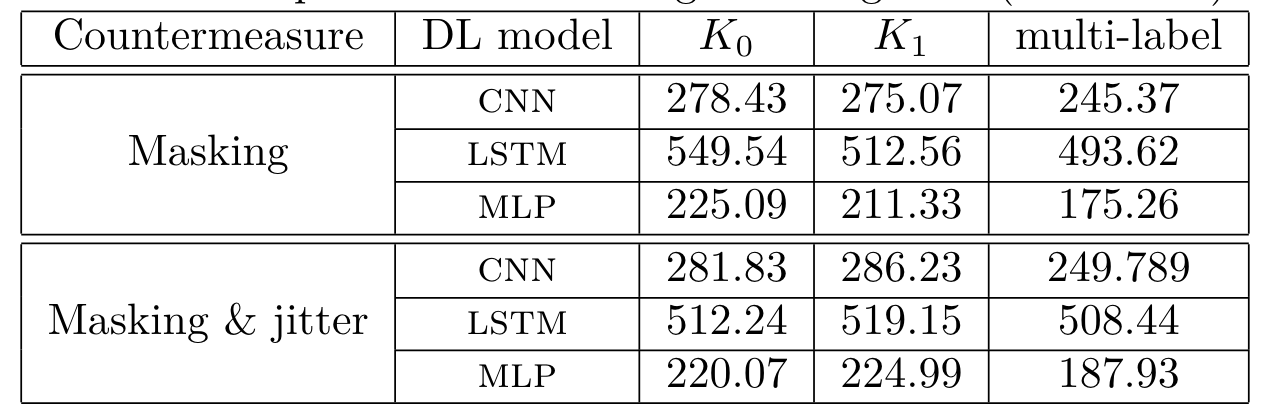
DPAv2
在DPAv2数据集上的训练时间以及训练效果的表现如图5、图6所示。
总结
Qian Guo, Vincent Grosso, and François-Xavier Standaert. Modeling soft analytical side-channel attacks from a coding theory viewpoint. IACR Cryptology ePrint Archive, 2018:498, 2018. ↩︎